访问数:309
TimesFM


详细介绍 - TimesFM
简介摘要:
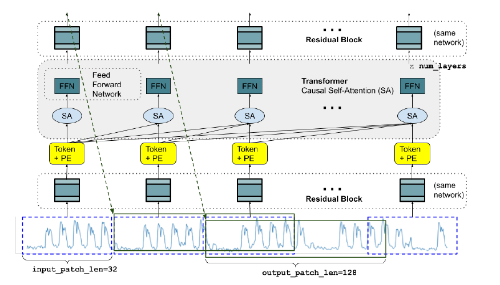
受用于自然语言处理(NLP)的大型语言模型的最新进展的启发,我们设计一个时间序列基础模型,用于预测其最佳零样本性能在各种公共数据集上,接近最先进的监督预测的准确性每个单独数据集的模型。我们的模型是基于对解码器式注意力的预训练具有输入补丁的模型,使用包括真实世界和合成的大型时间序列语料库数据集。在一组以前从未见过的预测数据集上进行的实验表明该模型可以在不同的领域、预测范围和时间粒度。
简介:
时间序列数据在零售、金融、制造、医疗保健和自然科学等各个领域无处不在。在其中许多领域中,时间序列数据最重要的用例之一是预测。时间序列预测对零售供应链优化、能源和交通预测以及天气预报等一些科学和工业应用至关重要。近年来,深度学习模型已成为预测丰富的多变量时间序列数据的一种流行方法,通常优于 ARIMA 或 GARCH 等经典统计方法。在几场预测比赛中,如M5比赛和IARAI Traffic4cast比赛,基于深度网络的解决方案表现非常好。
与此同时,我们见证了自然语言处理(NLP)领域在用于下游NLP任务的大型基础模型上的快速进展。大型语言模型(LLM)越来越受欢迎,因为它们可以用于生成文本、翻译语言、编写不同类型的创造性内容,以及以信息丰富的方式回答您的问题。他们接受了大量数据的训练,这使他们能够学习人类语言的模式。这使它们成为非常强大的工具,可以用于各种下游任务,通常是在零样本学习模式中。
项目信息:
模型地址:google/timesfm-1.0-200m · HF Mirror (hf-mirror.com)
--文 by AixTong.com--