相关资讯
标题:
工具:
简介:
中文提示词:
Windows 环境下通过 unsloth 在本地微调 deepseek 模型详细教程
发布时间:2025-03-26
原文地址:window环境下通过unsloth在本地微调deepseek模型详细教程_unsloth微调deepseek-CSDN博客
0 基础环境
操作系统:windows11
显卡:NVIDIA RTX 2060 6G显存
conda:已安装miniconda
上网:已具备科学上网
1 环境准备
1.1 CUDA环境准备
安装12.4版本CUDA。
1.2 conda项目环境准备
1.2.1创建conda项目环境
conda create -n LearnLangchain python=3.10
1.2.2 pycharm创建项目
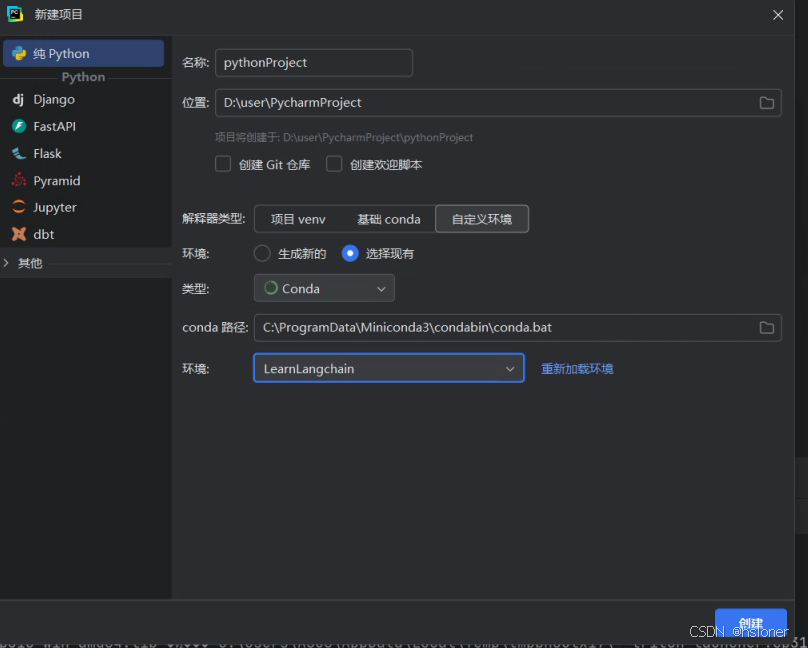
1.2.3 安装unsloth环境
# 安装torch pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124 # 安装unsloth,版本:2025.2.15 pip install unsloth # 安装triton pip install .\triton-3.2.0-cp310-cp310-win_amd64.whl
triton下载链接:https://github.com/woct0rdho/triton-windows/releases/download/v3.2.0-windows.post10/triton-3.2.0-cp310-cp310-win_amd64.whl
1.3 模型准备
pip install modelscope mkdir ./DeepSeek-R1-Distill-Llama-8B modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Llama-8B --local_dir ./DeepSeek-R1-Distill-Llama-8B
1.4 数据准备
https://huggingface.co/datasets/FreedomIntelligence/medica l-o1-reasoning-SFT
通过上面的链接下载数据文件。
2 逻辑实现
代码实现参考:DeepSeek R1 Distill高效微调入门实战 - 飞书云文档
2.1 引入环境变量,未引入会导致找不到c编译器和c标准库
import os # os.environ["UNSLOTH_USE_TRITON"] = "False" import sys sys.stdout.reconfigure(encoding='utf-8') os.environ['PYTHONIOENCODING'] = 'utf-8' os.environ["CL"] = "/utf-8" os.environ["CC"] = "C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.43.34808/bin\Hostx64/x64/cl.exe" os.environ["PATH"] += r";C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.43.34808/bin\Hostx64/x64" # 上面修改为你的实际路径 os.environ["INCLUDE"] = r"C:/Program Files (x86)/Windows Kits/10/Include/10.0.22621.0/; C:/Program Files (x86)/Windows Kits/10/Include/10.0.22621.0/ucrt; C:/Program Files (x86)/Windows Kits/10/Include/10.0.22621.0/um; C:/Program Files (x86)/Windows Kits/10/Include/10.0.22621.0/shared; C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.43.34808/include; C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.4/include" os.environ["LIB"] = r"E:/dev/conda/envs/LearnLangchain/libs; C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.43.34808/lib/x64; C:/Program Files (x86)/Windows Kits/10/Lib/10.0.22621.0/ucrt/x64; C:/Program Files (x86)/Windows Kits/10/Lib/10.0.22621.0/ucrt_enclave/x64; C:/Program Files (x86)/Windows Kits/10/Lib/10.0.22621.0/um/x64"
2.2 引入组件包,设定部分模型参数
from unsloth import FastLanguageModel import torch max_sep_length = 2048 dtype = None load_in_4bit = False
2.3 加载模型
model, tokenizer = FastLanguageModel.from_pretrained( model_name = "./DeepSeek-R1-Distill-Llama-8B", max_seq_length = max_sep_length, dtype = dtype, load_in_4bit = load_in_4bit, device_map = "cuda", )
2.4 构建模型训练提示词模板
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure
a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
{}
{}"""
EOS_TOKEN = tokenizer.eos_token
#
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}2.5 加载训练数据
from datasets import load_dataset
dataset = load_dataset("./medical-o1-reasoning-SFT/","en", split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)2.6 将模型设置成微调模式
# 加入此行代码,将模型转为训练模式 FastLanguageModel.for_training(model) model = FastLanguageModel.get_peft_model( model, r = 16, target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], lora_alpha = 16, lora_dropout = 0, bias = "none", use_gradient_checkpointing="unsloth", random_state=3407, use_rslora=False, loftq_config=None, )
2.7 训练模型
trainer = SFTTrainer( model = model, tokenizer = tokenizer, train_dataset = dataset, # 指定数据集中哪一列包含 训练文本(在 formatting_prompts_func 里处理) dataset_text_field = "text", # 最大序列长度,控制输入文本的最大 Token 数量 max_seq_length = max_sep_length, # 数据加载的并行进程数,提高数据预处理效率 dataset_num_proc = 2, args = TrainingArguments( # 每个 GPU/设备 的训练批量大小(较小值适合大模型) per_device_train_batch_size = 2, # 梯度累积步数(相当于 batch_size=2 × 4 = 8) gradient_accumulation_steps=4, # 预热步数(初始阶段学习率较低,然后逐步升高) warmup_steps = 5, # 最大训练步数(控制训练的总步数,此处总共约消耗60*8=480条数据) max_steps=60, # 学习率(2e-4 = 0.0002,控制权重更新幅度) learning_rate = 2e-4, # 如果 GPU 不支持 bfloat16,则使用 fp16(16位浮点数) fp16=not is_bfloat16_supported(), # 如果 GPU 支持 bfloat16,则启用 bfloat16(训练更稳定) bf16=is_bfloat16_supported(), # 每 10 步记录一次训练日志 logging_steps=10, # 使用 adamw_8bit(8-bit AdamW优化器)减少显存占用 optim="adamw_8bit", # 权重衰减(L2 正则化),防止过拟合 weight_decay=0.01, # 学习率调度策略(线性衰减) lr_scheduler_type="linear", # 随机种子(保证实验结果可复现) seed=3407, # 训练结果的输出目录 output_dir="outputs", ) ) trainer_stats = trainer.train()
2.8 保存模型
new_model_local = "DeepSeek-R1-Medical-COT" model.save_pretrained(new_model_local) tokenizer.save_pretrained(new_model_local) model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit", )
2.9 测试微调后的模型
question_2 = "Given a patient who experiences sudden-onset chest pain radiating to the neck and left arm,
with a past medical history of hypercholesterolemia and coronary artery disease, elevated troponin I levels, and tachycardia,
what is the most likely coronary artery involved based on this presentation?"
inputs = tokenizer([prompt_style.format(question_2, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])附录:
访问次数:65