相关资讯
标题:
工具:
简介:
中文提示词:
华为推出 VeLoRA:便宜且内存高效的大模型训练算法
发布时间:2024-06-03
尽管大型语言模型(LLMs)已成为处理许多语言处理任务的强大工具,但训练和微调这些模型仍然需要大量的计算和内存。
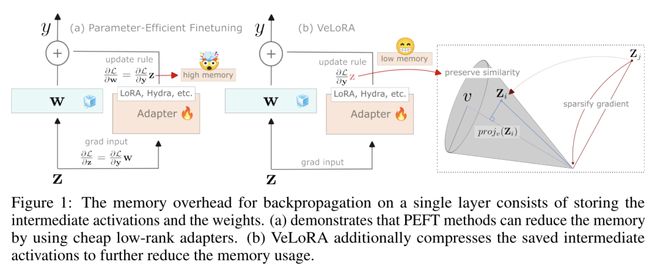
在这项工作中,来自华为诺亚方舟实验室的研究团队确定并描述了使用梯度下降技术有效收敛模型所需的重要组件。在此过程中,他们发现用于实现反向传播的中间激活可以被过度压缩,而不会导致性能下降。为此,他们提出了一种便宜且内存效率高的算法,将其用于微调和预训练 LLM。所提出的算法只需将 token 分成较小的子 token,然后在前向传递过程中将它们投影到一个固定的一维子空间上。然后在后向传递过程中对这些特征进行粗略重构,从而执行更新规则。
研究证实,在 VTAB-1k 微调基准上,该算法与许多 PEFT 方法相比都非常有效。此外,在对 LLaMA 进行微调时,该算法的性能优于 QLoRA,而且在大规模 C4 数据集上,该算法的性能与其他节省内存的预训练方法相比也很有竞争力。
论文地址:https://arxiv.org/abs/2405.17991
访问次数:285