一、前言
在计算机视觉领域,人体姿态识别是一个极具挑战性和应用价值的任务。它广泛应用于动作捕捉、虚拟现实、智能监控等诸多场景。而MediaPipe作为谷歌推出的一个开源机器学习框架,为人体姿态识别提供了强大的支持和便捷的实现方式。本文将详细介绍如何使用MediaPipe进行人体姿态识别,包括环境搭建、代码实现以及结果展示等环节。

二、MediaPipe简介
Mediapipe 是由Google开发的开源框架,旨在构建跨平台的机器学习管道,特别适用于处理多媒体数据如视频和图像。它提供了一套库和工具,让开发者能够快速将人工智能(AI)和机器学习(ML)技术应用到自己的应用程序中。无论是在移动设备、网页应用还是嵌入式系统上,MediaPipe都能提供高效的性能表现。
核心功能
MediaPipe Tasks:用于部署解决方案的跨平台API和库。
MediaPipe Models:预训练的、即用型模型。
MediaPipe Model Maker:允许使用自定义数据定制模型。
MediaPipe Studio:在浏览器中可视化、评估和基准测试解决方案。
核心特性
GPU加速:利用图形处理单元(GPU)进行快速处理,能够处理最具挑战性的多媒体任务。
并行处理:能够同时执行多项任务,如处理多个视频流或运行多个计算机视觉模型。
OpenCV集成:集成了强大的开源计算机视觉库OpenCV,轻松添加视频捕获、处理和渲染功能。
TensorFlow支持:与Google的机器学习工具TensorFlow集成,便于添加预训练或自定义模型。
多语言支持:支持C++、Java和Python等流行语言。
预训练模型:提供即用型模型,便于快速集成到应用中。
模型定制:通过MediaPipe Model Maker,可以使用特定数据定制模型。
高效的设备端处理:针对设备端机器学习进行了优化,无需依赖云处理即可实现实时性能。
应用场景
MediaPipe在多个领域都有广泛的应用,以下是一些典型的应用场景:
人体姿态估计:在健身、体育和医疗保健领域通过精确的人体姿态估计技术产生了重大影响。它可以实时检测和追踪身体关节和运动,被用于运动反馈应用、体育表现分析和物理治疗辅助。
视频通话增强:在COVID-19疫情期间,远程通信和视频会议应用的使用大幅增加。MediaPipe在改进这些技术方面发挥了重要作用,添加了动态帧调整和手势控制等功能。
增强现实滤镜设计:可用于创建类似Snapchat或Instagram的基于增强现实(AR)的人脸滤镜。这个过程涉及多个步骤,首先是准确识别人脸特征。
智能安防:在安防监控系统中,MediaPipe可以用于身份验证和行为分析。
医疗健康:某医院采用MediaPipe的面部追踪技术,帮助医生监测患者的面部表情变化,从而评估其心理状态。
MediaPipe是一个功能强大且易于使用的多媒体处理框架,无论你是初学者还是资深开发者,都能从中受益。它提供了丰富的预训练模型和工具,支持多种平台和语言,能够满足各种实时处理视觉数据的需求。
三、环境搭建
安装MediaPipe和OpenCV
在开始之前,我们需要安装MediaPipe和OpenCV库。这两个库将共同完成视频捕获和姿态检测的任务。在Windows命令行环境下,可以使用以下命令进行安装:
pip install mediapipe opencv-python
四、代码实现
实时监测姿态识别
导入必要的Python模块
import cv2 import mediapipe as mp
初始化MediaPipe姿态检测对象
mpPose = mp.solutions.pose # 导入姿态检测模块
pose_mode = mpPose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5) # 创建姿态检测对象并设置参数
mpDraw = mp.solutions.drawing_utils # 导入绘图工具
捕获视频并进行姿态检测
cap = cv2.VideoCapture(0) # 使用摄像头捕获视频,参数0表示使用默认摄像头
while True:
success, img = cap.read() # 读取视频帧
img = cv2.flip(img, 1) # 翻转图像,使画面更加自然
results = pose_mode.process(img) # 对图像进行姿态检测
if results.pose_landmarks:
mpDraw.draw_landmarks(img, results.pose_landmarks, mpPose.POSE_CONNECTIONS) # 绘制姿态关键点和连接线
cv2.imshow("img", img) # 显示图像
if cv2.waitKey(1) & 0xFF == ord("q"): # 按下'q'键退出循环
break
cap.release() # 释放摄像头资源
cv2.destroyAllWindows() # 关闭所有OpenCV窗口效果图如下

视频的姿态识别的实现
与上述实时监测的原理相同,代码如下
import cv2
import mediapipe as mp
# 打开本地视频文件
cap = cv2.VideoCapture('./demo.mp4')
# 获取视频的宽度、高度和帧率
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
# 定义视频编码器和输出文件
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter('output.mp4', fourcc, fps, (width, height))
# 初始化MediaPipe姿态检测对象
mp_pose = mp.solutions.pose
pose = mp_pose.Pose(min_detection_confidence=0.5, min_tracking_confidence=0.5)
mp_drawing = mp.solutions.drawing_utils
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
results = pose.process(frame_rgb)
if results.pose_landmarks:
mp_drawing.draw_landmarks(frame, results.pose_landmarks, mp_pose.POSE_CONNECTIONS)
# 写入输出文件
out.write(frame)
cv2.imshow('Pose Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()效果图如下
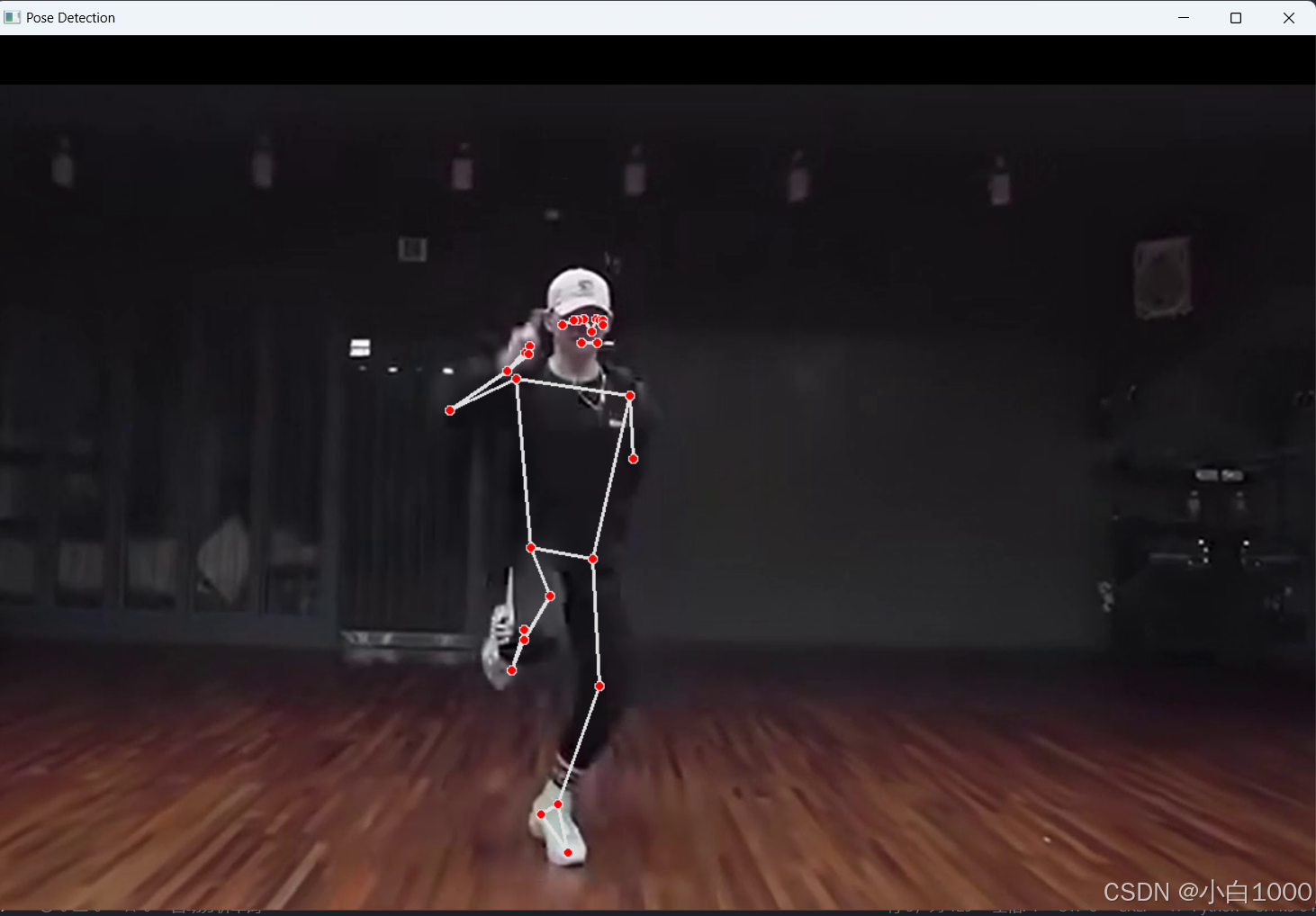
图片的姿态识别的实现
import cv2
import mediapipe as mp
# 初始化MediaPipe的绘制工具和姿态检测模块
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.pose
# 设置绘制关键点和连接线的样式
DrawingSpec_point = mp_drawing.DrawingSpec((0, 255, 0), 2, 2)
DrawingSpec_line = mp_drawing.DrawingSpec((0, 0, 255), 2, 2)
# 初始化姿态检测对象,设置为静态图片模式
pose = mp_pose.Pose(static_image_mode=True)
# 读取图片
file = 'input.jpg'
image = cv2.imread(file)
image_height, image_width, _ = image.shape
# 将BGR图像转换为RGB图像
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 处理RGB图像,获取姿态检测结果
results = pose.process(image_rgb)
# 在图像上绘制姿态关键点和连接线
if results.pose_landmarks:
mp_drawing.draw_landmarks(
image, results.pose_landmarks, mp_pose.POSE_CONNECTIONS,
DrawingSpec_point, DrawingSpec_line
)
# 打印某个关键点的坐标,例如鼻子的坐标
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_height})'
)
# 保存绘制后的图像
cv2.imwrite('image-pose.jpg', image)
# 释放姿态检测对象
pose.close()效果图如下

五、总结与展望
本文详细介绍了基于MediaPipe的人体姿态识别的实现过程,包括环境搭建、代码实现以及结果展示等环节。MediaPipe强大的姿态检测功能和便捷的API接口,使得我们能够快速搭建起人体姿态识别系统,并在实际应用中发挥重要作用。未来,我们可以进一步探索如何结合深度学习等技术,提高姿态识别的准确性和鲁棒性,拓展其在更多领域的应用,如体育训练、康复医疗等。
希望本文对你有所帮助,如果你对MediaPipe人体姿态识别有更深入的研究或应用,欢迎在评论区分享你的经验和见解。
————————————————
原文链接:https://blog.csdn.net/m0_74152166/article/details/145228710