本文翻译自:InfoWorld
原文地址:5 easy ways to run an LLM locally | InfoWorld(2024-4-25)
翻译工具:百度翻译,同时根据文章的上下文进行了适当调整,使其更符合中文描述方式。
文章配图:所有配图为原文中的配图
本文摘要:
本文介绍了在本地部署大模型的几种方法和工具:GPT4All、基于命令行的LLM、ollama、h2oGPT、PrivateGPT、与RTX聊天、llamafile、Jan、Opera、LM Studio。
【序】
如果你有合适的工具,在你自己的系统上部署一个大型语言模型可能会非常简单。以下是如何在桌面上使用像Meta的新Llama 3这样的LLM。
【正文】
像ChatGPT、Claude.ai和Meta.ai这样的聊天机器人可能非常有用,但您可能并不总是希望您的问题或敏感数据由外部应用程序处理。在平台上尤其如此,在这些平台上,你的互动可能会被人类审查,并以其他方式用于帮助训练未来的模型。
一种解决方案是下载一个大型语言模型(LLM)并在您自己的机器上运行它。这样一来,外部公司就永远无法访问您的数据。这也是尝试一些新专业模型的快速选择,如Meta的新Llama 3,它经过了编码调整,以及Seamless M4T,它旨在实现文本到语音和语言翻译。
运行自己的LLM听起来可能很复杂,但有了正确的工具,它会出奇地容易。而且许多型号的硬件要求并不疯狂。我已经在两个系统上测试了本文中提供的选项:一个是带有英特尔i9处理器、64GB RAM和英伟达GeForce 12GB GPU(可能没有参与运行该软件的大部分工作)的戴尔PC,另一个是只有16GB RAM的M1芯片的Mac。
请注意,可能需要一点研究才能找到一个在您的任务中运行良好并在桌面硬件上运行的模型。而且,很少有人能像你习惯的ChatGPT(尤其是GPT-4)或Claude.ai这样的工具那样好。命令行工具LLM的创建者Simon Willison在去年夏天的一次演示中认为,即使本地模型的响应是错误的,运行它也是值得的:
「在你的笔记本电脑上运行的[一些]会产生疯狂的幻觉——我认为这实际上是运行它们的一个很好的理由,因为在你的电脑上运行弱模型是了解这些东西如何工作及其局限性的一种更快的方式。」
同样值得注意的是,开源模型不断改进,一些行业观察人士预计,它们与商业化的领先者之间的差距将缩小。
使用GPT4All运行本地聊天机器人
如果你想要一个在本地运行、不会给其他地方发送数据的聊天机器人,GPT4All提供了一个易于设置的桌面客户端以供下载。它包括在您自己的系统上运行的模型选择,还有Windows、macOS和Ubuntu的版本。
当您第一次打开 GPT4All 桌面应用程序时,您将看到大约10个(截至本文撰写之时)可以在本地运行的模型的下载选项。其中包括 Meta AI 的模型 Llama-2-7B 聊天。如果你有API密钥,你也可以设置OpenAI的GPT-3.5和GPT-4(如果你有访问权限)供非本地使用。
GPT4All 接口的模型下载部分一开始有点令人困惑。在我下载了几个模型后,我仍然可以选择全部下载。这表明下载不起作用。然而,当我检查下载路径时,模型就在那里。
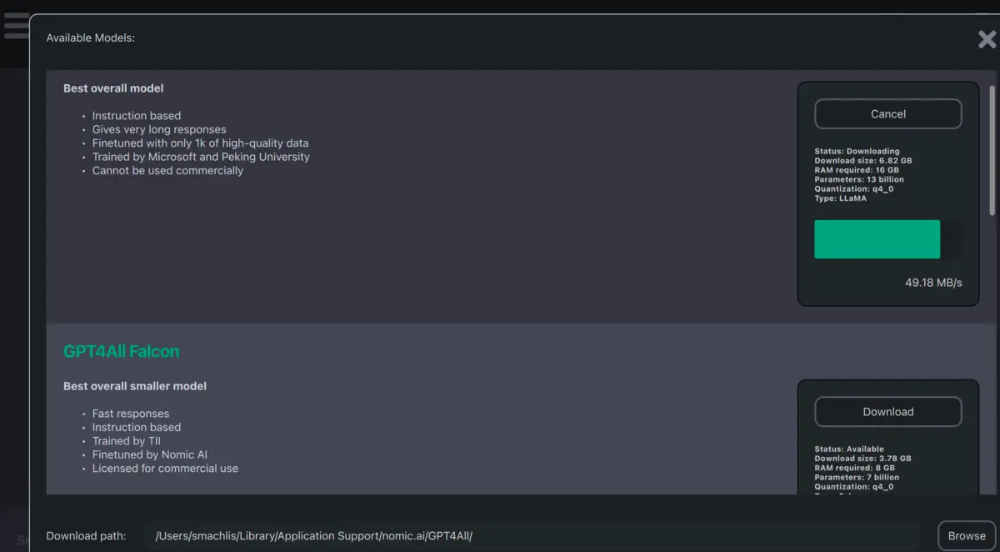
GPT4All 中模型下载接口的一部分。一旦我打开应用程序的使用部分,我下载的模型就会自动出现。
一旦建立了模型,聊天机器人界面本身就很干净,易于使用。方便的选项包括将聊天复制到剪贴板并生成响应。
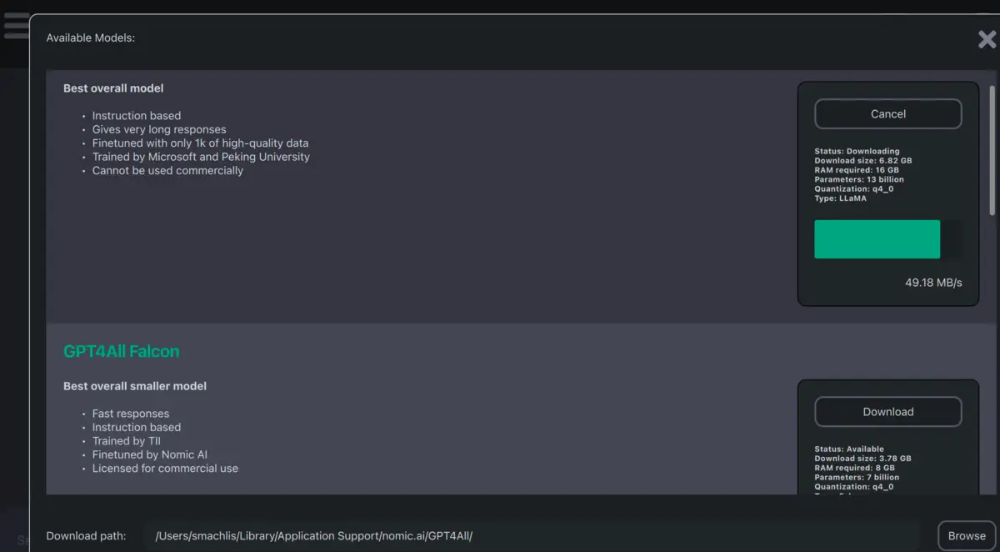
还有一个测试版 LocalDocs 插件,可以让你在本地与自己的文档“聊天”。您可以在“设置”>“插件”选项卡中启用它,在那里您将看到“LocalDocs插件(BETA)设置”标题和在特定文件夹路径创建集合的选项。
该插件正在进行中,文档警告说,即使 LLM 可以访问您添加的专家信息,它仍可能“产生幻觉”(编造东西)。尽管如此,这是一个有趣的功能,随着开源模型的能力越来越强,它可能会得到改进。
除了聊天机器人应用程序,GPT4All 还绑定了 Python、Node 和命令行界面(CLI)。还有一种服务器模式,可以让你通过一个结构非常像 OpenAI 的 HTTP API 与本地LLM交互。目标是通过更改几行代码,让您将本地 LLM 替换为 OpenAI。
命令行上的LLM
Simon Willison 的 LLM 是我见过的在自己的机器上本地下载和使用开源 LLM 的更简单的方法之一。虽然您确实需要安装Python来运行它,但不需要接触任何 Python 代码。如果你在 Mac 电脑上使用 Homebrew,只需使用:
如果您在Windows计算机上,请使用您最喜欢的安装Python库的方式,例如:
LLM 默认使用 OpenAI 模型,但您可以使用插件在本地运行其他模型。例如,如果您安装 gpt4all 插件,您将可以从 gpt4all 访问其他本地模型。还有用于 Llama、MLC 项目和 MPT-30B 的插件,以及其他远程模型。
在命令行上安装一个插件,名称为llm Install model:
您可以使用命令 llm-models-list 查看所有可用的模型——远程和已安装的模型,包括每种模型的简要信息。

要将查询发送到本地LLM,请使用以下语法:
选择正确的LLM
如何选择模型?InfoWorld 的14个非 ChatGPT LLM 是一个来源,尽管您需要检查哪些 LLM 是可下载的,以及它们是否与 LLM 插件兼容。您还可以前往 GPT4All 主页,向下滚动到与 GPT4All 兼容的模型的模型资源管理器。falcon-q4_0选项是一款评价很高、相对较小的模型,具有允许商业使用的许可证,所以我用它开始。
然后,我问了falcon-q4_0一个类似于ChatGPT的问题,但没有发出单独的命令下载模型:
这是 LLM 用户体验如此优雅的原因之一。如果本地系统上不存在 GPT4All 模型,LLM 工具会在运行查询之前自动为您下载它。下载模型时,您将在终端中看到进度条。
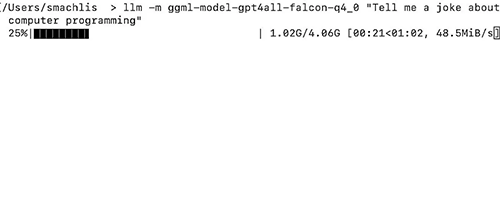
这个笑话本身并不怎么样 ——“程序员为什么关掉电脑?因为他想看看它是否还在工作!”—— 但事实上,这个查询确实起了作用。如果结果令人失望,那是因为模型性能或用户提示不足,而不是 LLM 工具。
还可以为LLM中的模型设置别名,以便可以使用较短的名称来引用它们:
要查看所有可用的别名,请输入:llm alias。
Meta 的 Llama 模型的 LLM 插件需要比 GPT4All 更多的设置。阅读 LLM 插件的 GitHub 仓库的详细信息。请注意,通用 llama-2-7b-chat 确实在我的工作 Mac 上运行了,配置是 M1 Pro 芯片,只有16GB的RAM。与为没有GPU的小型机器优化的 GPT4All 模型相比,它运行得相当慢,在我更健壮的家用电脑上表现更好。
LLM 还有其他功能,比如一个参数标志,可以让你继续之前的聊天,以及在 Python 脚本中使用它的能力。9月初,该应用程序获得了生成文本嵌入的工具,这是文本含义的数字表示,可用于搜索相关文档。您可以在 LLM 网站上看到更多信息。Willison 是流行的Python Django 框架的联合创建者,他希望社区中的其他人能为 LLM 生态系统贡献更多插件。
你桌面上的Llama模型:Ollama
Ollama 是一种比 LLM 更容易下载和运行模型的方法。然而,之前该项目仅限于macOS和Linux,目前 Windows 的版终于问世。我在此测试了Mac版本。
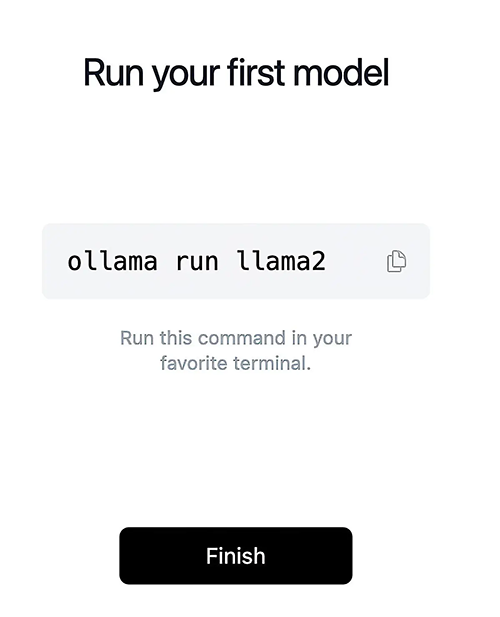
通过点击安装是一种优雅的体验。尽管 Ollama 是一个命令行工具,但只有一个命令的语法为 Ollama 运行模型名称。与LLM一样,如果模型还没有在您的系统上,它将自动下载。
您可以在这个网址上查看可用模型的列表 https://ollama.ai/library ,截至本文撰写之时,它包括基于 Llama 的模型的几个版本,包括Llama 3、Code Llama、CodeUp 和 medllama2,后者经过微调以回答医学问题。
Ollama GitHub 仓库的自述文件中列出了一些有用的模型规格和建议,“你应该至少有8GB的 RAM 来运行3B型号,16GB的内存来运行7B型号,32GB的内存去运行13B型号。”在我的16GB RAM Mac上,7B Code Llama的性能出奇地快。它将回答有关bash/zsh shell 命令以及 Python 和 JavaScript 等编程语言的问题。
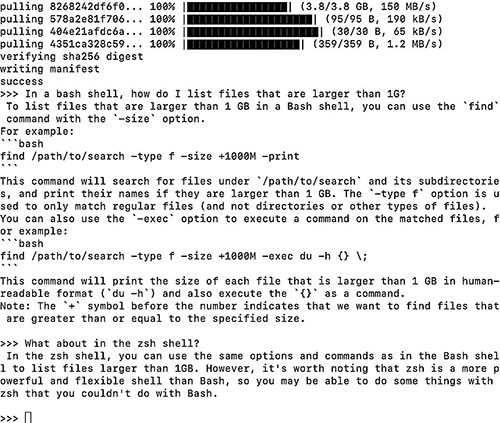
尽管 Code Llama 是家族中最小的模型,但它在回答一个R编码问题方面做得很好,如果不完美的话,这个问题会让一些更大的模型绊倒:“Write R code for a ggplot2 graph where the bars are steel blue color.”代码是正确的,只是其中两行代码中有两个额外的右括号,在我的IDE中很容易找到并处理。我怀疑更大的 Code Llama 本可以做得更好。
Ollama 还有一些额外的功能,比如 LangChain 集成和使用 PrivateGPT 运行的能力,除非你查看 GitHub repo 的教程页面,否则这些功能可能并不明显。
您可以在终端窗口中运行PrivateGPT,并在每次有问题时将其调出。我期待着在我的家用电脑上使用 Ollama Windows 版本。
与您自己的文档聊天:h2oGPT
H2O.ai 在自动机器学习方面已经工作了一段时间,因此该公司进入聊天LLM领域是很自然的。它的一些工具最适合熟悉该领域的人使用,但按照期指导安装 h2oGPT 聊天桌面应用程序测试版本快速而直接,即使对于机器学习新手也是如此。
您可以在 gpt.h2o.ai 上访问网络上的演示版本(显然,这不是使用系统本地的LLM),这是一种在将界面下载到您自己的系统之前了解您是否喜欢该界面的有用方法。
您可以按照此处的安装说明下载该应用程序的基本版本,但查询自己文档的能力有限。
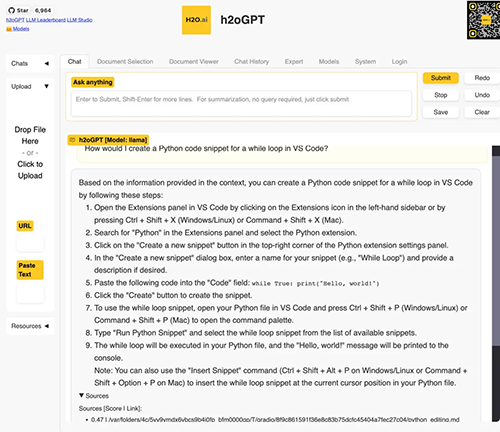
无需添加自己的文件,您就可以将该应用程序用作通用聊天机器人。或者,您可以上传一些文档并询问有关这些文件的问题。兼容的文件格式包括PDF、Excel、CSV、Word、文本、标记等。测试应用程序在我的 16GB Mac 上运行良好,尽管较小型号的结果无法与带GPT-4的付费版 ChatGPT 相比(一如既往,这是模型的功能,而不是应用程序的功能)。h2oGPT UI 为有一定经验或知识的用户提供了一个专家选项卡,其中包含许多配置选项。这为更有经验的用户提供了尝试改进其结果的选项。
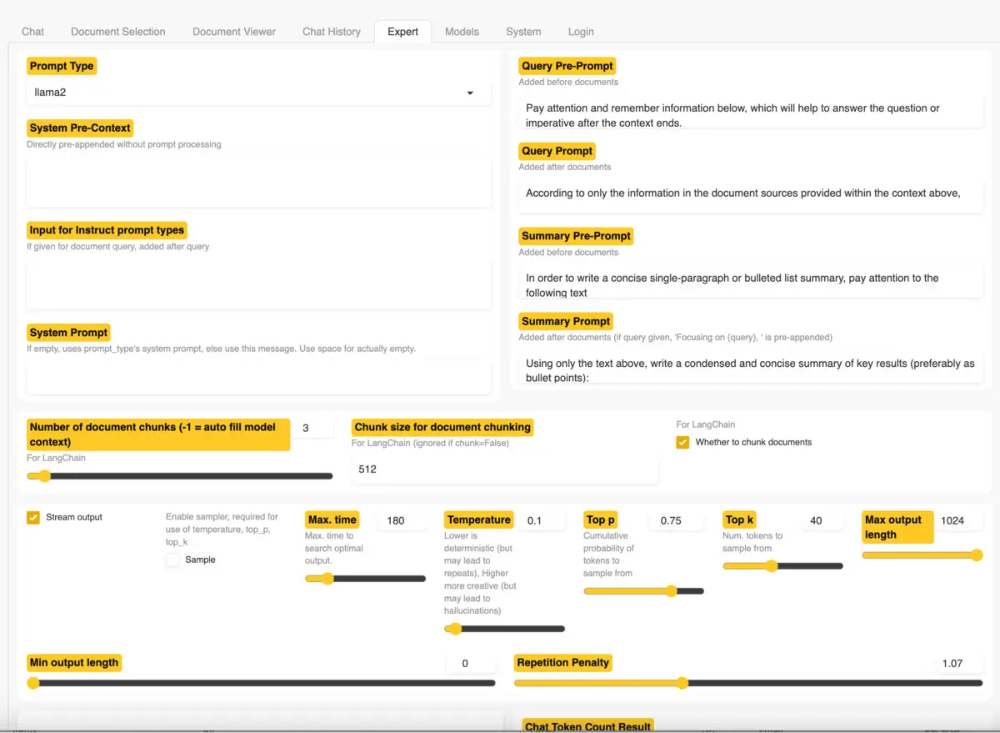
如果您想对流程进行更多控制,并为更多模型提供选项,请下载完整的应用程序。对于带有 GPU 或仅带有 CPU 的系统,有适用于Windows 和 macOS 的一键安装程序。请注意,Windows版本与我的 Windows 防病毒软件不太融洽,因为它没有签名。我熟悉H2O.ai 的其他软件,代码在 GitHub 上也有,所以我愿意下载并安装它。
Rob Mulla,现就职于H2O.ai,在他的频道上发布了一段关于在 Linux 上安装该应用程序的 YouTube 视频。尽管视频已经发布了几个月,应用程序用户界面似乎也发生了变化,但视频中仍然有有用的信息,包括关于 H2O.ai LLM 的有用解释。
轻松但缓慢的数据聊天:PrivateGPT
PrivateGPT 也是旨在让您使用自然语言查询自己的文档,并获得生成式人工智能的响应。此应用程序中的文档可以包括几十种不同的格式。README 中说,确保数据“100%私有,任何时候都不会有数据离开您的执行环境。您可以在没有互联网连接的情况下使用文档并提出问题!”
PrivateGPT 的特点是可以脚本化使用数据文件,将其分割成块,创建“向量”(文本含义的数字表示),并将这些向量存储在本地Chroma 矢量存储中。当你提出问题时,该应用程序会搜索相关文档,并将其发送给 LLM 以生成答案。
如果您熟悉 Python 以及如何设置 Python 项目,您可以克隆完整的 PrivateGPT 库并在本地运行它。如果你对 Python 不太了解,你也可以检出作者 Iván Martínez 为会议研讨会设置的项目的简化版本,它更容易设置。
该版本的 README 文件包括详细的说明,这些说明不需要 Python 的专业知识。repo 附带了一个 source_documents 文件夹,里面是各种文档,但您可以删除这些文档并添加自己的文档。
PrivateGPT 在终端的“与自己的文档聊天”应用程序中包含了你可能最想要的功能,但文档警告说,它不适合生产。一旦你运行它,你可能会明白为什么:即使是小型号的选项在我的家用电脑上运行也很慢。但请记住,家庭互联网的早期也非常缓慢。我预计这些类型的个人项目会加快速度。
运行本地LLM的更多方法
本地运行LLM的方法不止这五种,从其他桌面应用程序到从头开始编写脚本,都有不同程度的设置复杂性。
Jan
Jan是一个相对较新的开源项目,旨在通过“开放、本地优先的产品”实现人工智能访问的“民主化”。该应用程序下载和安装简单,界面在可定制性和易用性之间取得了很好的平衡。这是一个令人愉快的应用程序。
选择在 Jan 中使用的模型是相当愉快的。在应用程序的中心中,如下所示,有30多种模型的描述,并可供一键下载,其中包括一些我没有测试的带有视觉的模型。您也可以以 GGUF 格式导入其他文件。如果您的系统不适合运行 Jan 中心中列出的模型,则会显示“内存不足”标签。
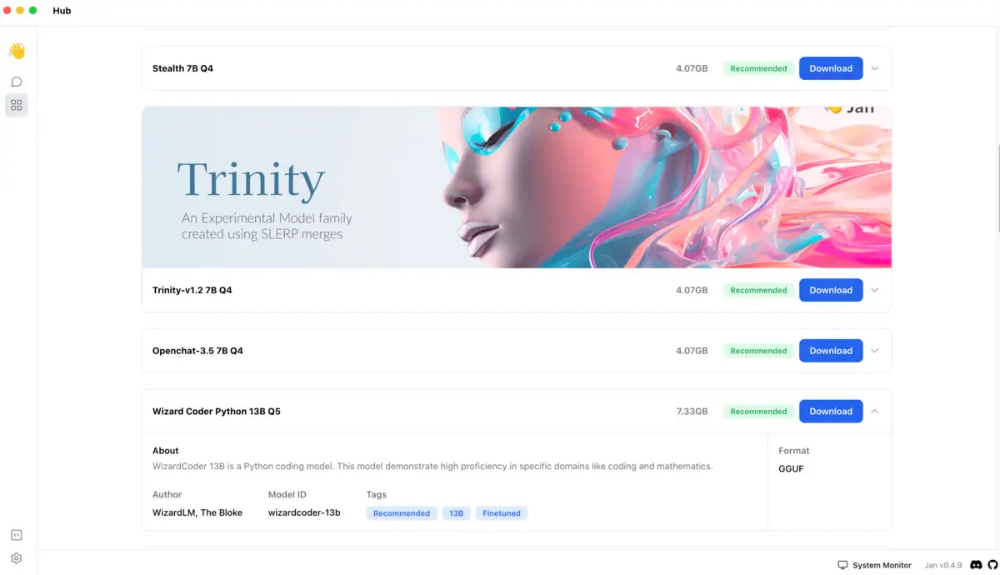
Jan 的聊天界面包括一个右侧面板,可以设置 LLM 的系统说明和调整参数。在我的工作 Mac 上,我下载的一个模型在启动时被标记为“设备速度慢”,有人建议我关闭一些应用程序以释放 RAM。无论你是否是 LLM 新手,在启动生成式 AI 应用程序时很容易忘记释放尽可能多的RAM,所以这是一个有用的提醒。(我的电脑上打开了很多标签的Chrome可能会占用内存;关闭它解决了这个问题。)
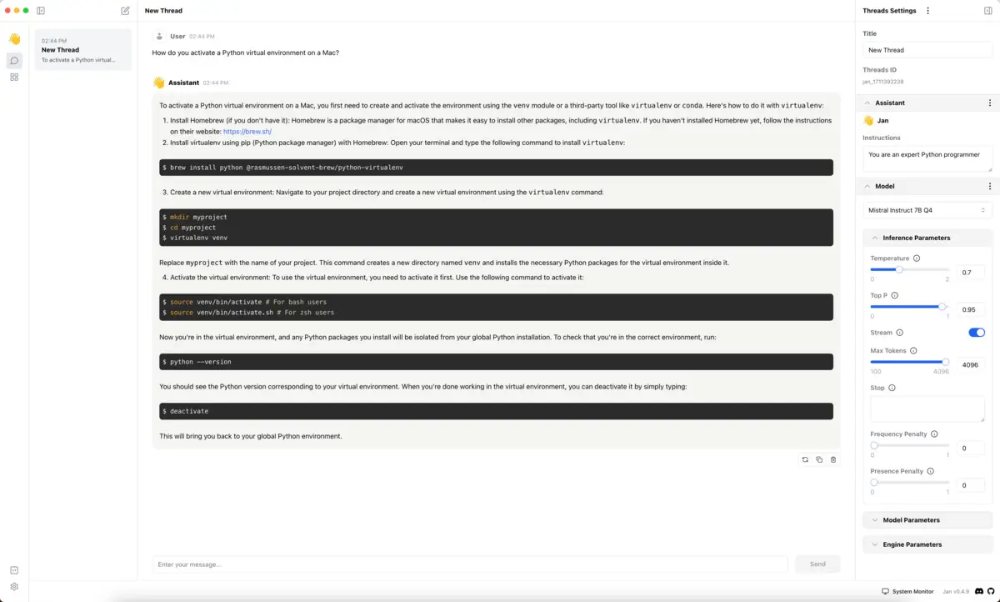
一旦我释放了RAM,应用程序中的流式响应就非常快了。
除了在本地运行 LLM 之外,Jan 还允许您从云中使用 OpenAI 模型。而且,您可以将 Jan 设置为使用远程或本地API服务器。
当我在2024年3月测试该应用程序时,Jan的项目文档仍然有点稀疏,尽管好消息是该应用程序的大部分使用起来相当直观,但并不是全部。我在 Jan 错过的一件事是上传文件和与文档聊天的能力。在GitHub上搜索后,我发现你确实可以通过在模型设置中打开“检索”来上传文件。但是,我无法上传 .csv 或 .txt 文件。两者都不受支持,尽管在我尝试之前这一点并不明显。不过PDF有效。值得注意的是,尽管不是 Jan 的错,但我测试的小型模型在检索增强生成方面做得并不好。
Jan 相对于 LM Studio(见下文)的一个关键优势是,Jan 是许可 AGPLv3 许可证下的开源作品,只要任何衍生作品也是开源的,就可以不受限制地进行商业使用。LM Studio 对个人使用是免费的,但网站上说你应该填写 LM Studio@Work 申请表才能在工作中使用它。Jan 适用于 Windows、macOS 和 Linux。
Opera
如果你只想用一种超级简单的方式与当前网络工作流程中的本地模型聊天,那么 Opera 的开发者版本是可能的。它不提供与文件聊天等功能。你还需要登录 Opera 帐户才能使用它,即使是本地模型,所以我不相信它像这里介绍的大多数其他选项那样私密。但是,这是在工作流程中测试和使用本地LLM的一种方便方法。
Opera One的开发者流中提供了本地LLM,您可以从其网站下载。
首先,打开Aria Chat侧面板——这是屏幕左下角的顶部按钮。这里默认使用 OpenAI 的模型和谷歌搜索。
要选择本地模型,你必须单击“开始”,就像你在做默认的一样,然后在屏幕顶部附近有一个选项“选择本地人工智能模型”
选择该选项,然后单击“转到设置”浏览或搜索模型,如 8B或70B 规格的 Llama 3。
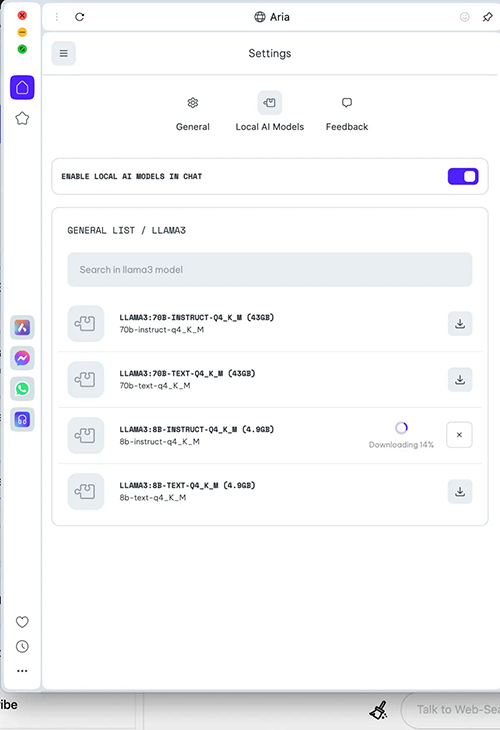
对于那些硬件非常有限的人,Opera建议 Gemma:2b-instruct-q4_K_M。
在你的模型下载后,有点不清楚如何回去开始聊天。点击屏幕左上角的菜单,你会看到一个“新聊天”按钮。确保再次点击“选择本地人工智能模型”,然后选择你下载的模型;否则,您将使用默认的OpenAI聊天。
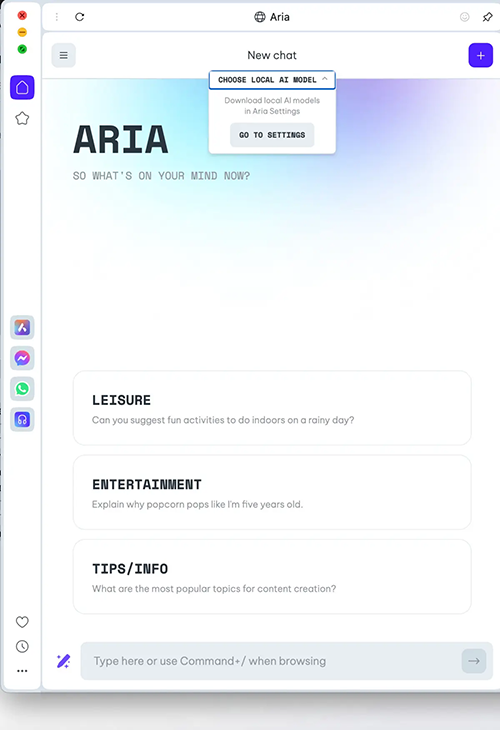
在 Opera 中聊天最吸引人的是使用一个本地模型,在你的侧板生成人工智能工作流程中,这个模型感觉类似于现在熟悉的副驾驶。Opera 总部位于挪威,并表示它对所有用户都符合GDPR,只要需要登录云帐户。但我仍然会再三考虑将此模型用于任何高度敏感的事情。
与RTX聊天
Nvidia 的 Chat with RTX 演示应用程序设计为回答有关一个指定目录中的文档的问题。自2月推出以来,Chat with RTX 可以使用本地运行的 Mistral 或 Llama 2 LLM。您需要一台带有 Nvidia GeForce RTX 30 系列或更高 GPU、至少 8GB 显存的 Windows PC 来运行应用程序。你还需要一个强大的互联网连接,其下载量高达35GB。
使用RTX聊天提供了一个非常易于使用的简单界面。单击该图标将启动一个 Windows 终端,该终端运行脚本以在默认浏览器中启动应用程序。
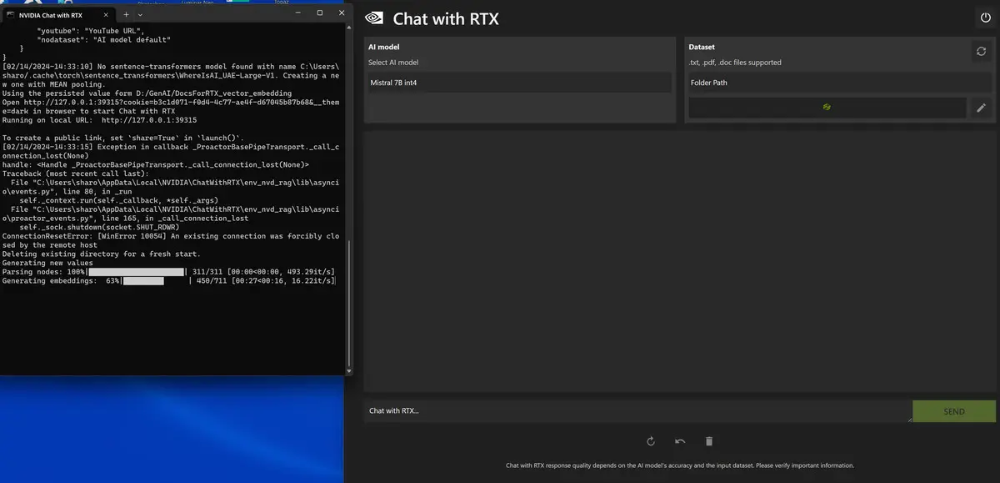
选择 LLM 和文件的路径,等待应用程序为您的文件创建向量——您可以在终端窗口中按照进度进行操作——然后您就可以提问题了。响应包括指向 LLM 用于生成其答案的文档的链接,如果您想确保信息准确,这很有帮助,因为模型可能会根据它所知道的其他信息而不仅仅是您的特定文档进行回答。该应用程序目前支持.txt、.pdf和.doc文件以及通过URL提供的YouTube视频。
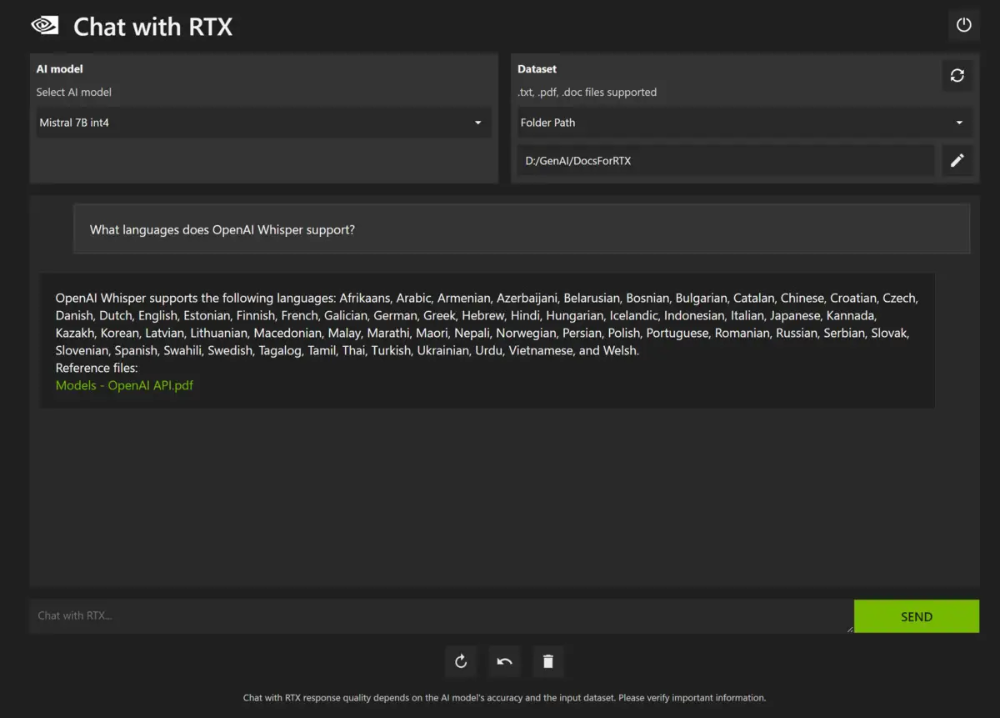
请注意,使用 RTX 聊天不会在子目录中查找文档,因此您需要将所有文件放在一个文件夹中。如果要向文件夹中添加更多文档,请单击数据集右侧的刷新按钮以重新生成向量。
llamafile
Mozilla 的 llamafile 于11月底发布,允许开发人员将大型语言模型的关键部分转换为可执行文件。它还附带了一个软件,可以下载GGUF 格式的 LLM 文件,导入它们,并在本地浏览器内聊天界面中运行它们。
为了运行 llamafile,该项目的自述文件建议使用下面的命令下载当前服务器版本
然后,下载您选择的模型。我读过关于 Zephyr 的好文章,所以我找到一个Hugging Face上的版本,并下载。
现在,您可以使用在终端中运行模型
将 zephyr 替换为您的模型所在的任何位置,等待加载,然后在浏览器中打开 http://127.0.0.1:8080 .您将看到一个带有各种聊天选项的打开屏幕:
在底部输入您的查询,屏幕将变成一个基本的聊天机器人界面:

您可以使用 GitHub存储库上的本项目中的一个示例文件来测试运行单个可执行文件:mistral-7b-instruct、llava-v1.5-7b-server或wizardcoder-python-13b。
在 llamafile 发布的当天,本文中介绍的 LLM 项目的作者 Simon Willison 在一篇博客文章中说:“我认为这是现在开始在自己的计算机上运行大型语言模型(想想你自己的本地ChatGPT副本)的唯一最佳方式。”
虽然 llamafile 在我的Mac上非常容易启动和运行,但我在 Windows 上遇到了一些问题。目前,像 Ollama 一样,llamafile 可能不是即插即用 Windows 软件的首选。
LocalGPT
PrivateGPT 的衍生产品 LocalGPT 包括更多的模型选项,有详细的说明以及三个操作视频,包括17分钟的详细代码演练。对于这种安装和设置是否“简单”,可能会有不同的意见,但它看起来确实很有前景。不过,与 PrivateGPT 一样,文档警告说,仅在 CPU 上运行 LocalGPT 会很慢。
LM Studio
我尝试过的另一个桌面应用程序 LM Studio 有一个易于使用的聊天界面,但你可以自己挑选模型。如果你知道你想下载并运行哪个模型,这可能是一个不错的选择。如果你刚开始使用 ChatGPT,并且对如何最好地平衡精度和大小的知识有限,那么一开始所有的选择都可能有点让人不知所措。Hugging Face Hub 是 LM Studio 内置模型下载的主要来源,它有很多模型。
与其他 LLM 选项不同,它们都下载了我第一次尝试时选择的模型,我在 LM Studio 中下载其中一个模型时遇到了问题。另一个运行不好,这是我最大化 Mac 硬件的错,但我没有在模型选择时立即看到有关最低非GPU RAM建议。不过,如果你不介意耐心选择和下载模型,LM Studio在你运行聊天时会有一个漂亮、干净的界面。在撰写本文时,UI还没有内置的选项来在您自己的数据上运行LLM。
正如文档所述,LM Studio有一个内置服务器,可以“作为OpenAI API的替代品”,因此通过 API 使用 OpenAI 模型编写的代码将在您选择的本地模型上运行。
与 h2oGPT 一样,LM Studio 在 Windows 上发出警告,称其为未经验证的应用程序。LM Studio 代码在 GitHub 上不可用,也不是来自一个历史悠久的组织,所以并不是每个人都能安装它。
除了通过 h2oGPT 等应用程序使用预先构建的模型下载界面外,您还可以直接从 Hugging Face 下载和运行一些模型,Hugging Face 是一个人工智能平台和社区,包括许多 LLM。(并不是所有的模型都包括下载选项。)StarTree 的开发者倡导者 Mark Needham 对如何做到这一点有一个很好的解释,包括一段YouTube视频。他还在GitHub中提供了一些相关代码,包括使用本地LLM进行情绪分析。
Hugging Face 提供了一些关于如何在本地安装和运行可用模型的文档。
LangChain
另一个流行的选择是在 LangChain 中本地下载和使用 LLM,这是一个创建端到端生成人工智能应用程序的框架。这确实需要加快使用 LangChain 生态系统编写代码的速度。如果你了解 LangChain 的基本知识,你可以检出关于Hugging Face Local Pipelines、Titan Takeoff(需要Docker和Python)和 OpenLLM 的文档,以使用本地模型运行LangChain。OpenLLM 是另一个健壮的独立平台,旨在将基于 LLM 的应用程序部署到生产环境中。