5月22日,AI创业公司彩云科技发布了全新通用模型结构DCFormer,将直接挑战现在几乎所有大模型通用的Transformer架构。根据官方给出的相关论文实验证明,在三千亿级训练数据和70亿级模型参数量下,DCFormer效率是Transformer的两倍。
源码地址:https://github.com/Caiyun-AI/DCFormer
论文地址:https://arxiv.org/abs/2405.08553
以下是彩云科技CEO袁行远的发布原稿:
彩云科技董事会、各位股东、同学、用户以及关心彩云的朋友们:
大家好,很高兴向大家介绍我们研发的新模型结构 DCFormer!
01. GPT-4o 虽好,一句话还得要 4 元
最近几年风起云涌的大模型革命,让 AI 智能度有了飞跃,但其能耗也越来越大,所花费的训练和推理成本也越来越高。
据说去年仅 meta 一家,就购买了上百亿美元的显卡。刚刚在 OpenAI 春季发布会上展示的 GPT-4o,首先发布的改进就是速度提升一倍,价格下降一半,引来网友一片好评。但即使如此,当 128k 前文内容打满时,一次推理的成本仍然是 0.64 美元起步,就算 ai 只回复一个你好,一轮对话也需要消耗至少 4 块钱人民币。
大模型所需要的能源似乎很快就要吞噬地球,OpenAI 的 Sam Altman 甚至开始投资核聚变项目。
虽然研发更高效的模型结构势在必行,但处于风口浪尖的人工智能公司们很少有关注到模型结构创新,无论是中国的百模大战,还是全球其他地区的大模型,大部分都在疯狂烧钱购买 GPU 等算力。
他们在 7 年前开源的 Transformer 架构基础之上,使用从网上爬取的、加上自己的独门数据,重新训练出一个又一个百亿、千亿、万亿的模型权重文件。
PC 时代的英特尔+windows,移动时代的高通+安卓,重演为 ai 时代的英伟达+transformer。
02. 大模型的发展会被能耗锁死吗?
但就像三体里的智子锁死人类文明科技进展一样,如果底层模型没有突破,人工智能的进步终将停滞不前。
人人都说神经网络是个黑盒,但如果没有勇气和耐心打开这个黑盒,了解其中的运转原理,把黑盒变白盒,怎么可能做出改进底层模型的技术突破呢?
通过分析模型运转原理,我们才能知道智能的本质规律,从而可以改进模型,提高模型的运行效率。
“解开智能的科学的奥秘,实现通用人工智能”,正是彩云科技成立 10 年来,一直孜孜不倦追求的目标。
如果用烧牛肉来类比训模型,食材就是数据,火候就是算力,而模型就是你的锅,换成高压锅以后,煮熟牛肉的时间会变短(节省成本),同样的时间下,做出的牛肉会更软(效果提升),为了得到更好的烹饪效果,不能只靠增加火力和更换食材,锅也很重要,好的模型,可以极大地节省成本,提高效果,这就是模型的意义。
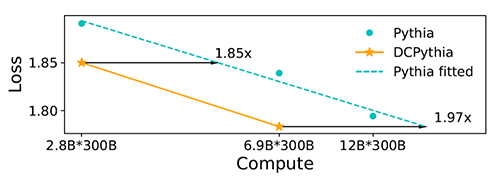
而我们提出的新模型架构 DCFormer,就是一口比 7 年前的 Transformer 更好的锅,通过对模型运行机制的多年探索,我们发现改进注意力机制,其性能有 1.7 到 2 倍的提升,超过之前所有有效改进的总和。
03. 套餐变单点,彩云科技 DCFormer 模型重大突破
到底我们怎么改的呢?
这要从大模型运行机制讲起。以“上海的简称”作为输入为例,大模型要解答这个问题,首先要把每个字或词拆分后变成向量(就是一堆数),然后输入给大模型:
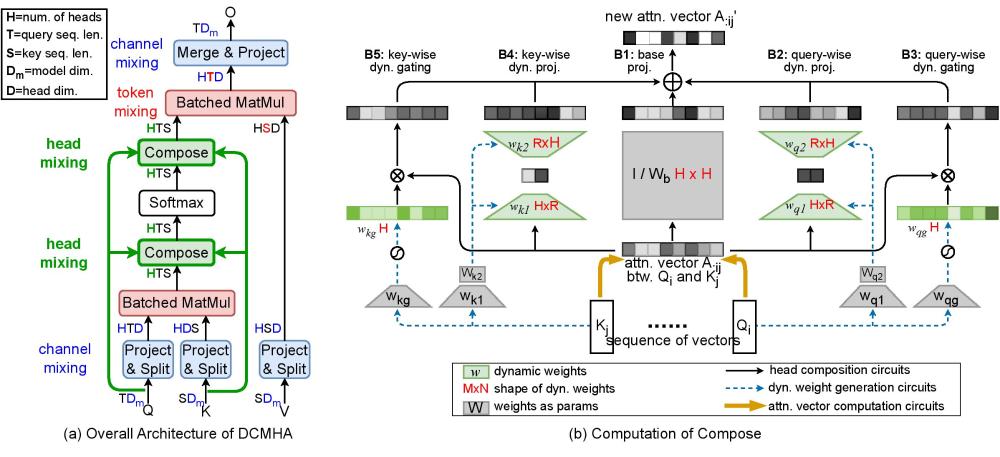
随后,每一层的每个输入向量,会分别乘以四个矩阵Q、K、V、O,这四个矩阵其实就是对输入的文本,进行以下两种操作:
1)查找(Q、K矩阵):根据当前词语的意义和位置,查找同一层的其他词语
2)变换(V、O矩阵):把查找出的词语,变成其他内容
一种典型的推理通路如下:
第一步,“简称”通过一个关联城市的 Q1K1 矩阵,查找到最关联的词语是“上海”,然后通过 V1O1 矩阵,把“上海”这个词向量转换为“沪”这个向量。
在此过程中,我们使用到了一组注意力矩阵 Q1、K1、V1、O1,完成了两种操作:关联城市和词语简称。
而多头注意力,就是针对每个输入,都有多组注意力矩阵。
比如我们换一个问题“中国的人口”,就需要使用一组新的注意力矩阵 Q2、K2、V2、O2,完成两个新的操作:Q2K2 关联国家和 V2O2 获取地区人口。
我们已经搞定了“上海的简称”和“中国的人口”。
那么问题来了,针对新问题“上海的人口”和“中国的简称”,我们还需要新的注意力矩阵吗?
原来的 Transformer 结构中,QKVO 四个矩阵是绑定的,因此,要解决新问题,必须重新再来 2 组注意力矩阵。
而 DCFormer 中,查找通路和变换通路可以根据输入的不同而任意组合,这样我们就可以用 2组 原来的注意力矩阵,组合出 4 种搭配,用 8 组注意力矩阵,组合出 64 种搭配。
Transformer 就像你去一家只能点套餐的麦当劳,麦辣鸡腿堡只能搭配可乐,奥尔良烤鸡只能搭配薯条,而 DCFormer 就是可以任意单点的麦当劳,快乐当然翻倍再翻倍!而且,你还可以只点半个麦辣鸡腿堡,组合半只奥尔良烤鸡。
通过对 Q、K、V、O 矩阵的线性组合,事实上 DCFormer 有无穷种可能!
在无数种可能的模型改进通路上,DCFormer 突破了过去7年的“智子封锁”,也开启了模型优化之路的无数种可能。
相同训练数据和算力下,一个改进后 69 亿参数的模型,拥有比 120 亿参数模型更好的效果。如果 GPT-4o 能够用上,推理一次 128k 上文的成本,就可能从 4 元变成 2 元。
而且 DCFormer 模型越大,效果越好,考虑到 ChatGPT 的巨大参数量,DCFormer 可能在千亿、万亿模型上效果更好,因此价格甚至可能下降到 1.5 元、1 元。Meta 的 100 亿美元显卡训练的模型,可能 50 亿美元就能够用。
DCFormer,你,值得拥有!
04. 权威学术认可与普惠开源
真有那么神吗?是我们自己吹牛吗?
2024 年 5 月 1 日,第 41 届国际机器学习大会 ICML 2024 发榜,彩云科技关于 DCFormer 的论文《Improving Transformers with Dynamically Composable Multi-Head Attention 》被高分录用。
ICML 作为国际机器学习领域的三大顶会之一,能够发布论文并获得高分的中国企业屈指可数。据一位评委透露,今年他准许发布的论文平均分为 4.25-6.33,而彩云 DCFormer 论文评分高达 7 分。这说明我们的工作获得了学术界的充分认可。
该论文已于今日在 arxiv 上发布,地址为:https://arxiv.org/abs/2405.08553
我们同时在 Github 上开源了 DCFormer 的模型代码、权重和训练数据集,地址为:https://github.com/Caiyun-AI/DCFormer
05. 以 1/10 的价格提供 10 倍的智能,但梦想不止于此
欢迎大家下载体验,批评指正。
不过,要特别说明的是,我们本次发布的工作是模型结构研究,我们需要在给定数据集和算力的情况下,才能对比模型效果,因此我们发布的模型主要是科研用途,并没有选最好的数据集和最大的算力。
希望体验 DCFormer 在天气预报、机器翻译和故事创作等彩云系列产品上的效果的同学,还请稍作等待,我们陆续会在彩云天气、小梦 V4、V5 等模型上应用 DCFormer 的成果。
随着模型效率的提升,彩云天气有希望在未来 3 小时到 12 小时,也实现如 2 小时预报那样的高准确率。之前你们看彩云天气,2 小时内精准到分钟,但超过半天还是经常出错。DCFormer 有助于我们实现未来 12 小时的高精度公里级预报,让你早上出门看看彩云,能更有信心的决定全天的行程。
目前小梦 V2、V3 创作几百字到一千字的内容,尚能保持逻辑通顺与描写细致,而 DCFormer 加持的 V4、V5 有希望扩展到 2 千到 5 千字,再通过一些故事工程的优化,我们希望一年内小梦可以轻松创作出达到专业作家水平的 5 万字长度的中篇故事,同时小梦角色扮演的故事体验也能达到专业编剧的水平。
DCFormer 已经开源,我更加期待计算机科学界和产业届能给我们带来更多研究与应用上的精彩演绎。
愿我们的工作能为通用人工智能搭上一块新积木,而大家一起努力,可以让通用人工智能之塔越来越高。
在不久的将来,我们不仅可以以当下 ChatGPT 十分之一的价格,提供出十倍的智能,还可以做出在所有领域都超越人类顶尖水平的 AGI!
To infinity and beyond!
袁行远
彩云科技 CEO
2024.5.15
--------------------------------
小编:不由得点赞,中国需要这样的AI公司!!!