

厂家:智谱AI
简介:
与上一代的 CogVLM 模型相比,CogVLM2 系列模型具有以下改进:
1、在不损失任何通用能力的前提下,在许多关键指标上有了显著提升,如在 OCRbench 基准上性能提升32%,在TextVQA基准上性能提升21.9%,且模型具备了较强的文档图像理解能力(DocVQA)等;
2、支持 8K 文本长度;
3、支持高达 1344 * 1344 的图像分辨率;
4、提供支持中英文双语的开源模型版本。
本次开源的两款以 Meta-Llama-3-8B-Instruct 为语言基座模型的 CogVLM2,模型大小仅 19B,但却能取得接近或超过 GPT-4V 的水平。

概要介绍:
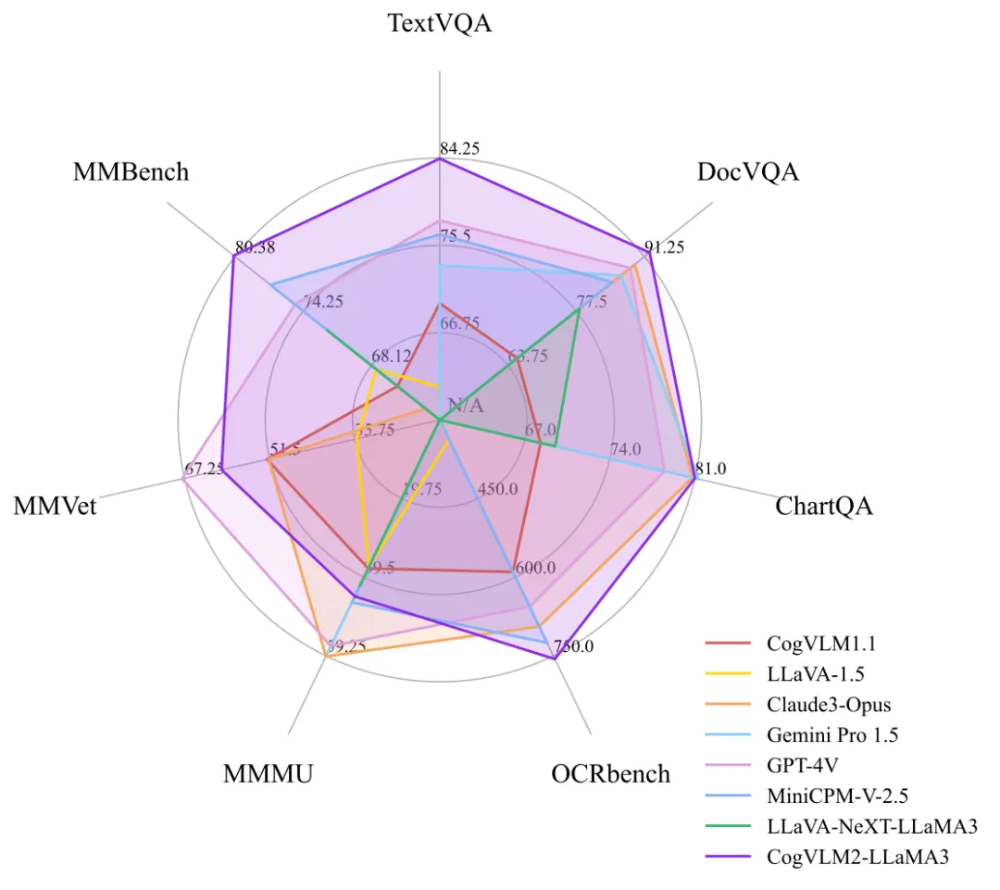
模型基准测试卫星图:
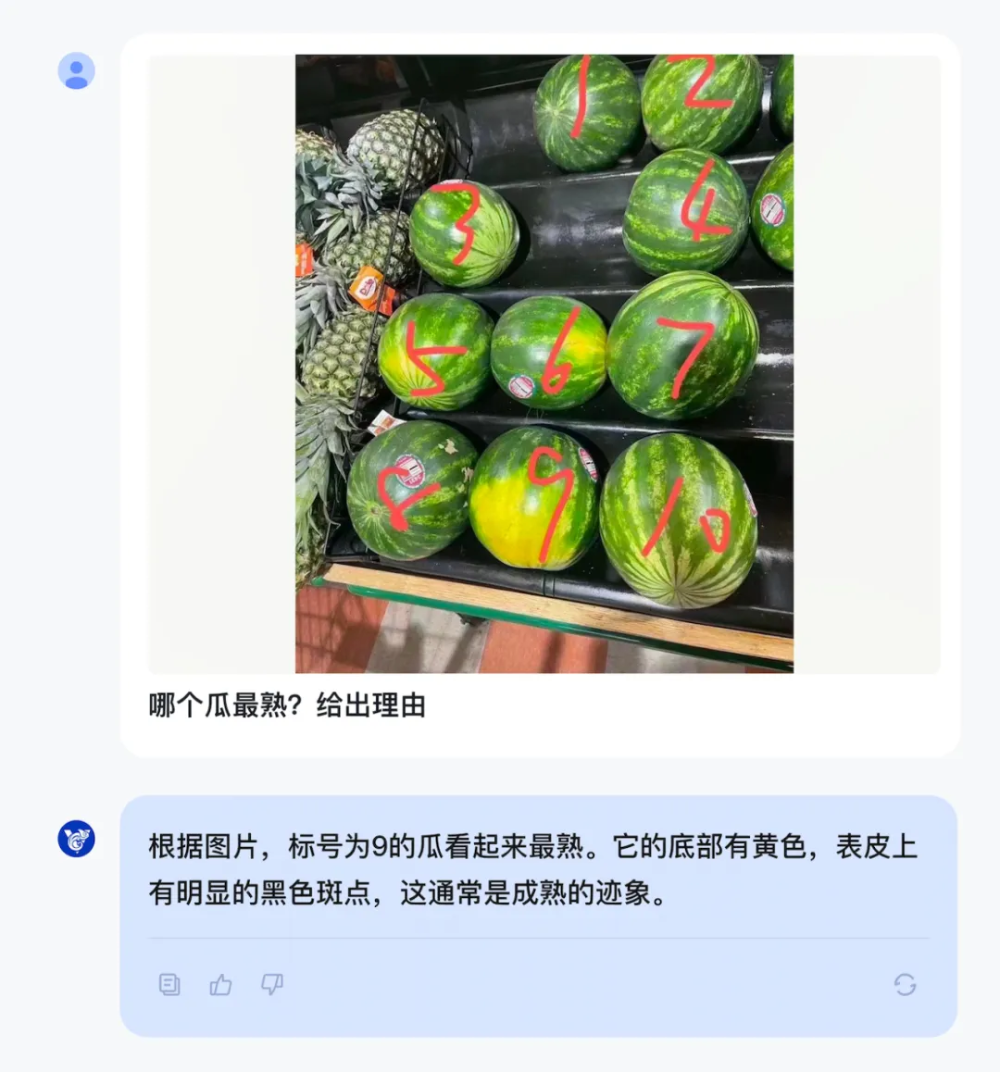
模型初步验证:
基于相同技术,功能更强大的GLM-V版本,将很快在”智谱清言“和开放平台上线。
代码仓库:Github:https://github.com/THUDM/CogVLM2
模型下载:
Huggingface:https://hf-mirror.com/THUDM
魔搭社区:https://modelscope.cn/models/ZhipuAI
始智社区:https://wisemodel.cn/models/ZhipuAI
技术文档:https://zhipu-ai.feishu.cn/wiki/OQJ9wk5dYiqk93kp3SKcBGDPnGf
Demo体验:https://modelscope.cn/studios/ZhipuAI/Cogvlm2-llama3-chinese-chat-Demo/summary
详细介绍:
一、模型架构
CogVLM2 继承并优化了上一代模型的经典架构,采用了一个拥有50亿参数的强大视觉编码器,并创新性地在大语言模型中整合了一个70亿参数的视觉专家模块。这一模块通过独特的参数设置,精细地建模了视觉与语言序列的交互,确保了在增强视觉理解能力的同时,不会削弱模型在语言处理上的原有优势。这种深度融合的策略,使得视觉模态与语言模态能够更加紧密地结合。
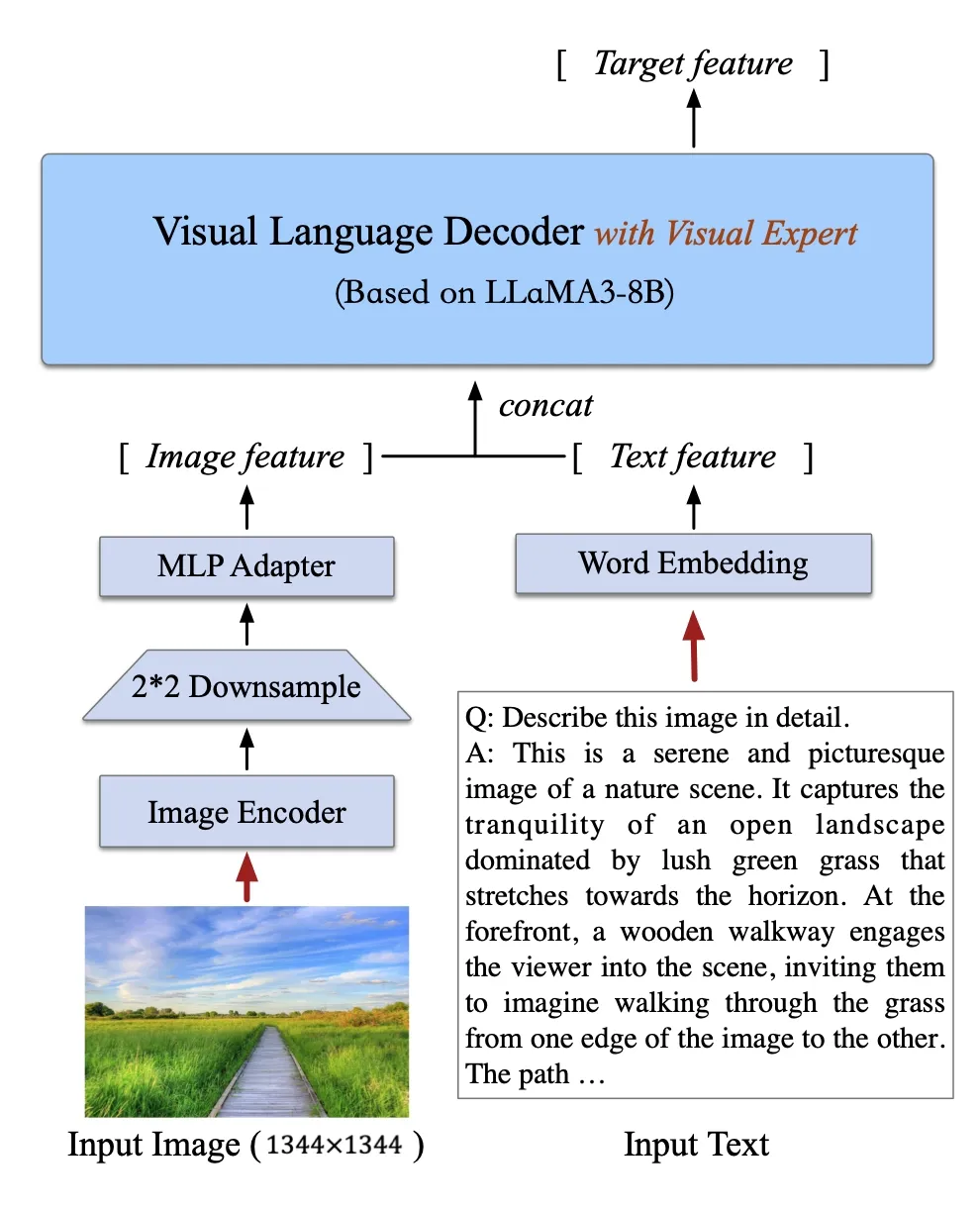
值得注意的是,尽管CogVLM2的总参数量为190亿,但得益于精心设计的多专家模块结构,每次进行推理时,实际激活的参数量仅约120亿。这种设计既保证了模型的强大性能,又显著提高了推理的效率。
为了更好地处理和理解高分辨率的文档或网页图片,CogVLM2能够支持高达1344分辨率的图像输入。为了提高处理此类高分辨率图像的效率,模型在视觉编码器后引入了一个专门的降采样模块。这个模块能够有效地提取视觉序列中的关键信息,大幅减少输入到语言模型中的序列长度,从而在确保模型性能的同时,显著提升了推理速度,实现了性能与效率的最佳平衡。
二、模型效果
为了更为严格地验证CogVLM的性能和泛化能力,我们在一系列多模态基准上进行了定量评估。这些基准包括 TextVQA、DocVQA、ChartQA、OCRbench、MMMU、MMVet、MMBench等。
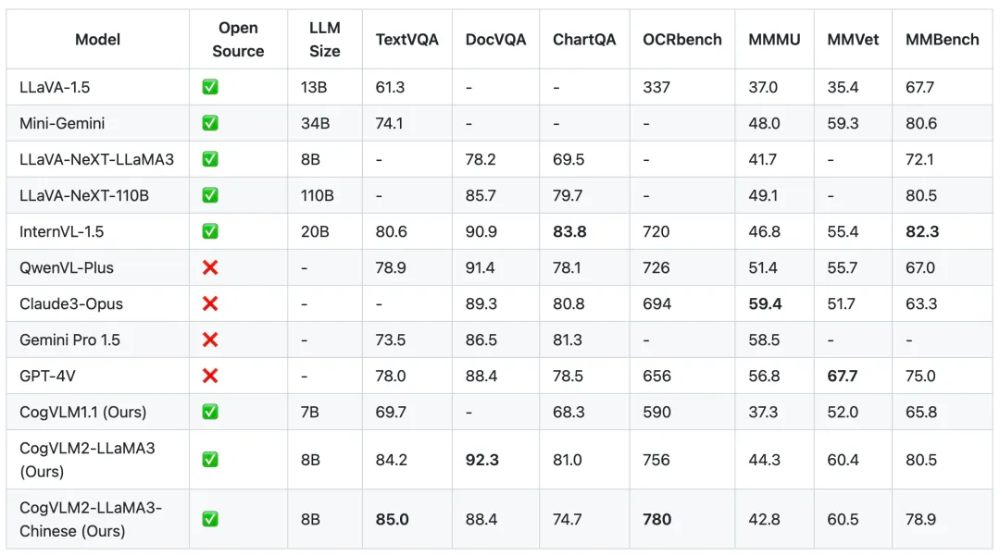
从上图可以看出,CogVLM2 的两个模型,尽管具有较小的模型尺寸,但在多个基准中取得 SOTA性能;而在其他性能上,也能达到与闭源模型(例如GPT-4V、Gemini Pro等)接近的水平。
三、推理&微调资源
由于开源版本采用了较小尺寸的语言基座模型,整个模型仅 19B,全量推理(BF16/PF16)需要 42GB 显存,Int4 量化版本,仅需要 16GB 显存。
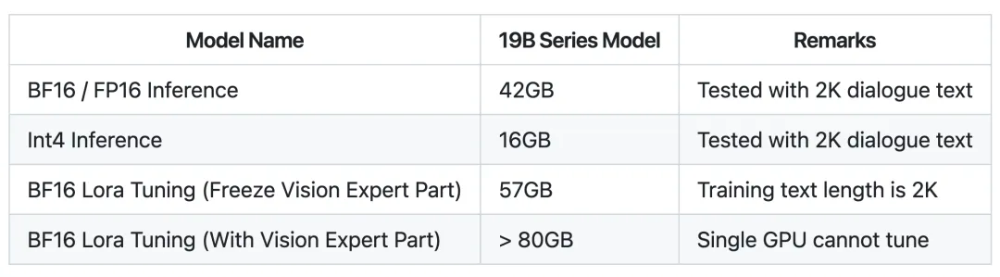
为了开发者能够将模型更好地应用于特定领域,我们同样提供了 Lora 微调代码。如果冻结视觉部分,BF16 Lora 微调则仅需 57GB 显存;如果同时对视觉部分进行 BF16 Lora 微调,则至少需要80GB 显存。
四、部分示例
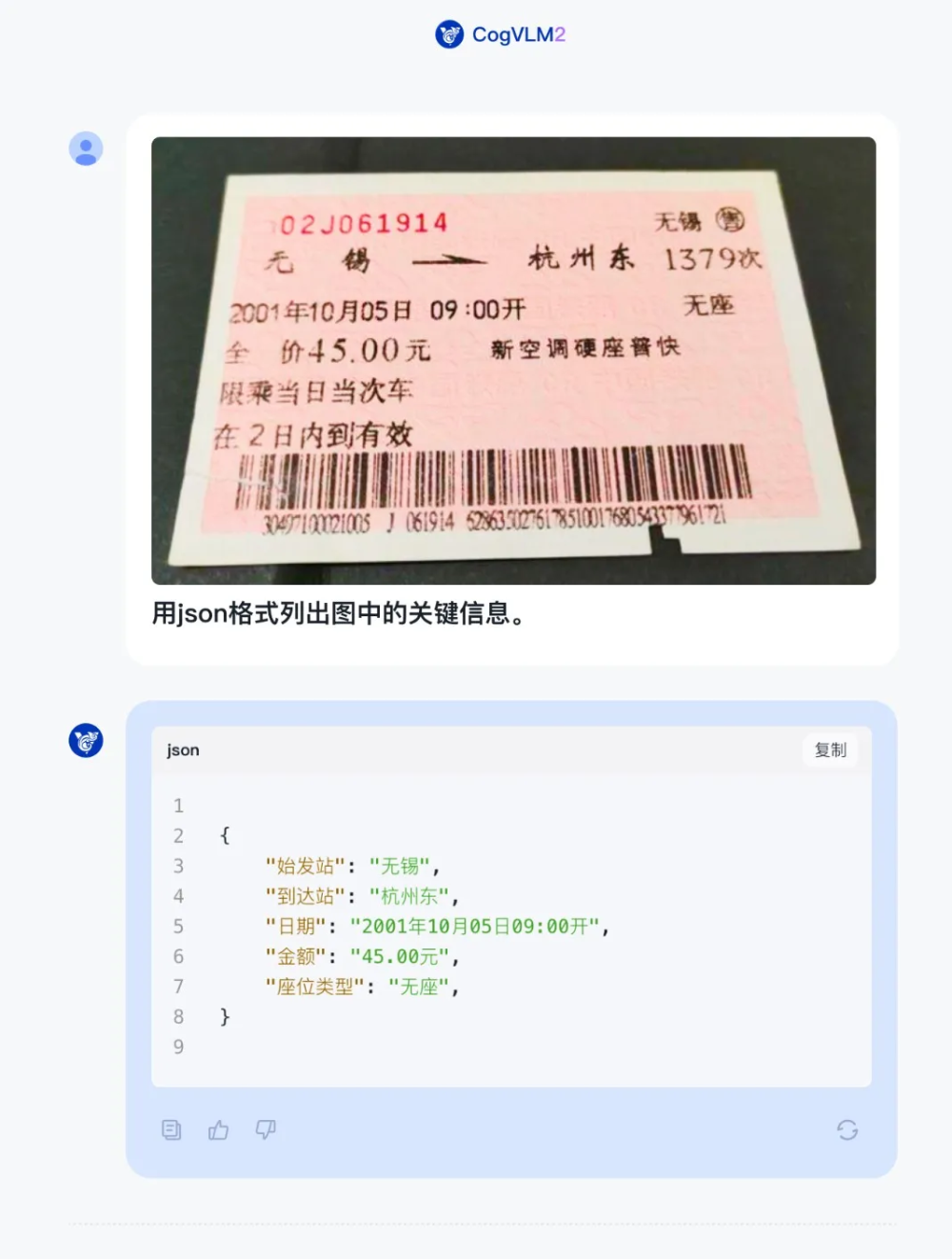
1、车票识别
2、房型识别

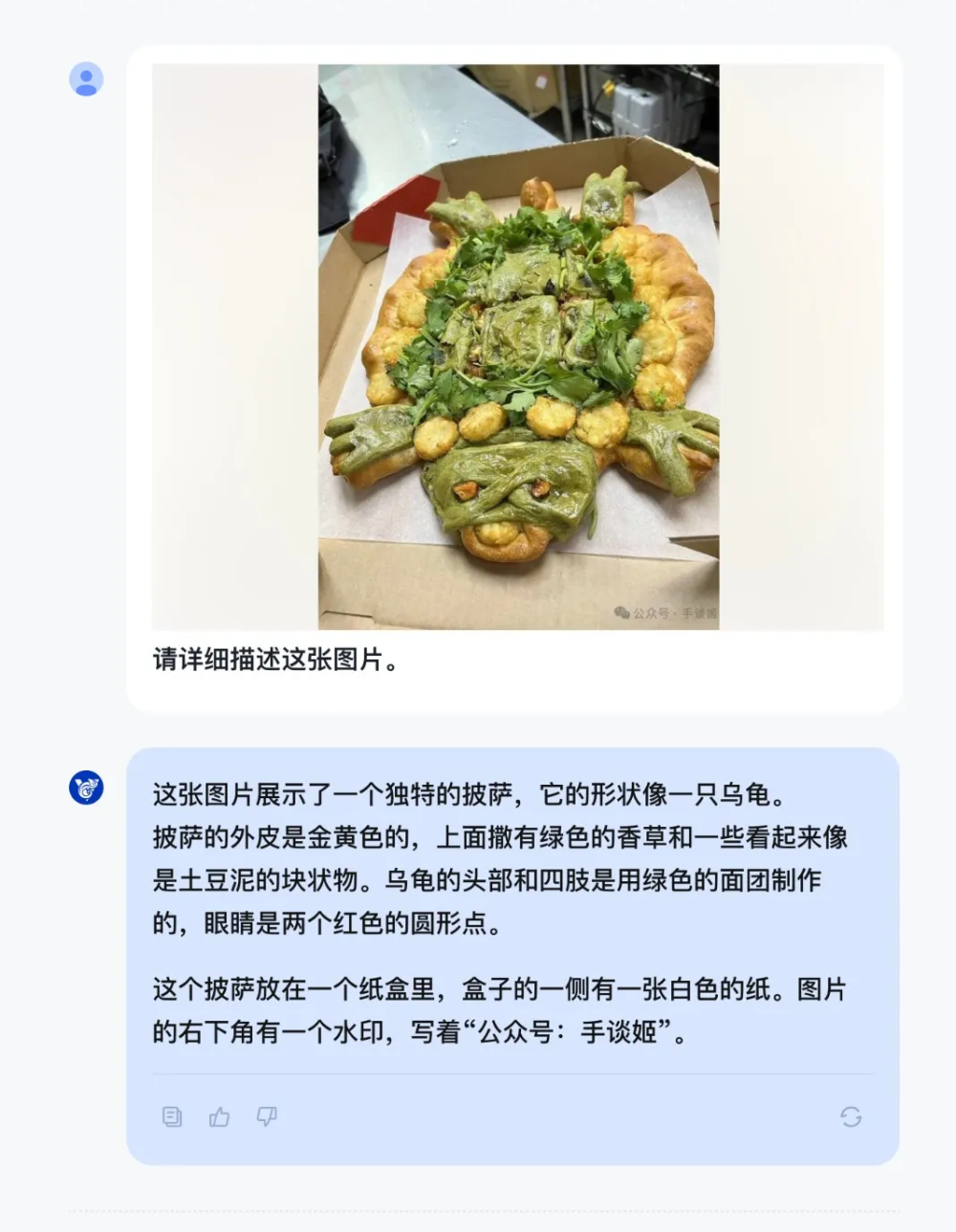
3、物体识别
4、手写识别

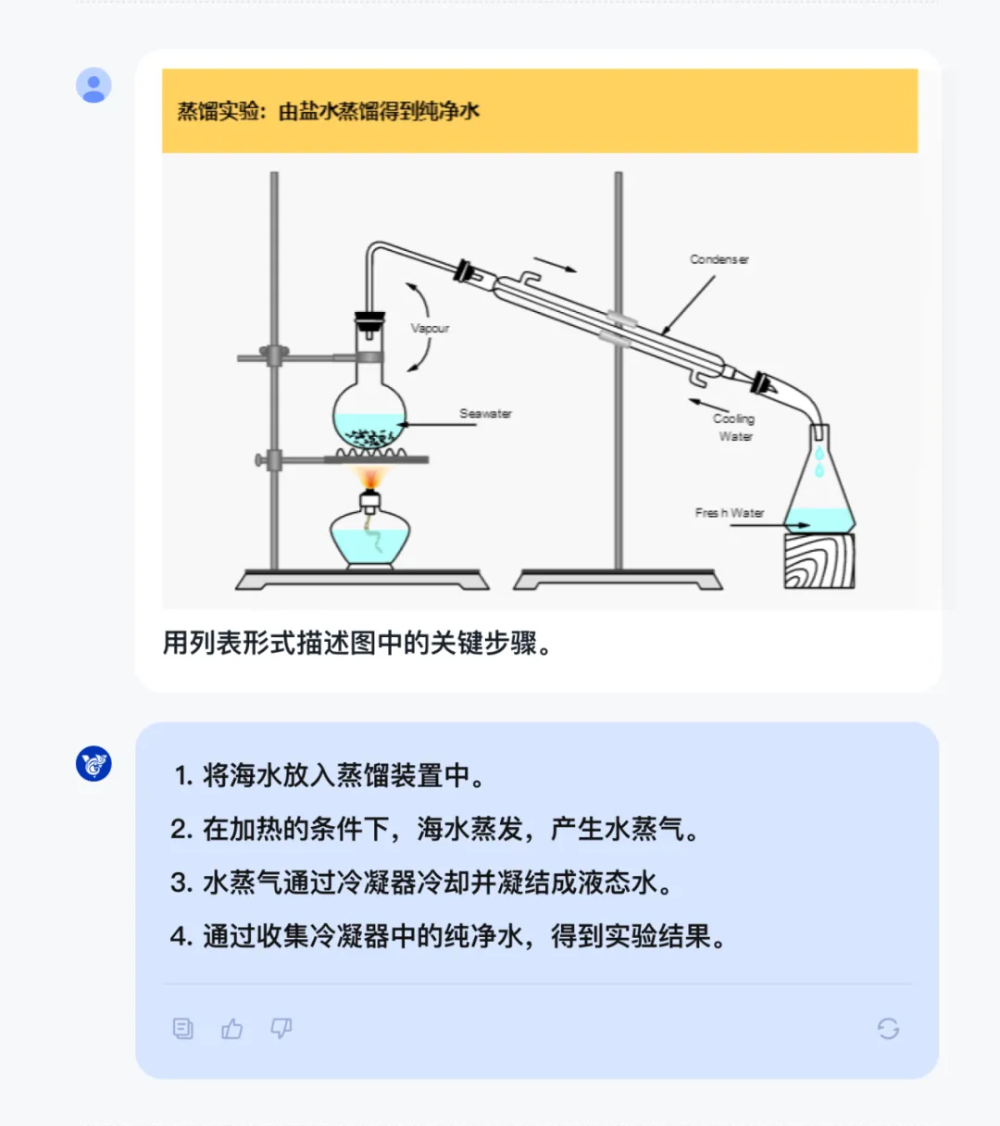
5、化学试验
6、甲骨文识别
