 访问数:2790
访问数:2790

简介:
AnythingLLM 是 Mintplex Labs Inc. 开发的一款开源 ChatGPT 等效工具,用于在安全的环境中与文档等进行聊天,专为想要使用现有文档进行智能聊天或构建知识库的任何人而构建。
开源地址:https://github.com/Mintplex-Labs/anything-llm

官网提供多个环境版本的下载:
苹果芯片的Mac、Intel芯片的Mac、Windows、Linux。相应版本请到官网下载。
当前版本:1.5.0
一、基本特性
特点
多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
支持多种文档类型:包括 PDF、TXT、DOCX 等。
简易的文档管理界面:通过用户界面管理向量数据库中的文档。
两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答
聊天中的引用标注:链接到原始文档源和文本。
简单的技术栈:便于快速迭代。
100% 云部署就绪。
“自带LLM”模式:可以选择使用商业或开源的 LLM。
高效的成本节约措施:对于大型文档,只需嵌入一次,比其他文档聊天机器人解决方案节省 90% 的成本。
完整的开发者 API:支持自定义集成。
支持的 LLM、嵌入模型和向量数据库
LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。
嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。
向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。
技术概览
整个项目设计为单线程结构,主要由三部分组成:收集器、前端和服务器。
collector:Python 工具,可快速将在线资源或本地文档转换为 LLM 可用格式。
frontend:ViteJS + React 前端,用于创建和管理 LLM 可使用的所有内容。
server:NodeJS + Express 服务器,处理所有向量数据库管理和 LLM 交互。
首先,收集器是一个实用的Python工具,它使用户能够快速将来自在线资源(如指定的YouTube频道的视频、Medium文章、博客链接等)或本地文档中的可公开访问数据转换为LLM可用的格式。该应用程序的前端采用了vitejs 和React进行构建,通过Node.js和Express服务器处理所有LLM交互和VectorDB管理。这种设计使得用户能够在直观友好的界面中进行操作,并且通过高效的服务器架构实现快速响应和管理大规模的数据。
二、操作和配置说明
下载
在AnythingLLM官网下载,并安装。
启动页

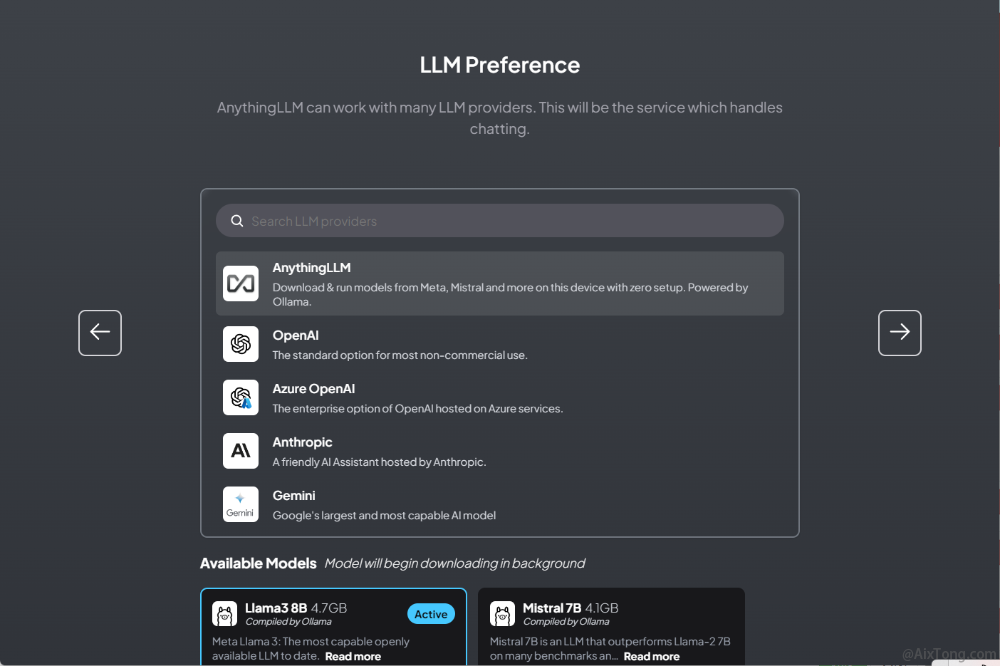
设置要使用的大语言模型
在下面的界面,选择模型,如AnythingLLM,或者在其下方选择其它指定模型。点击向右的键头按钮后,系统提示将在后台下载选定的模型。
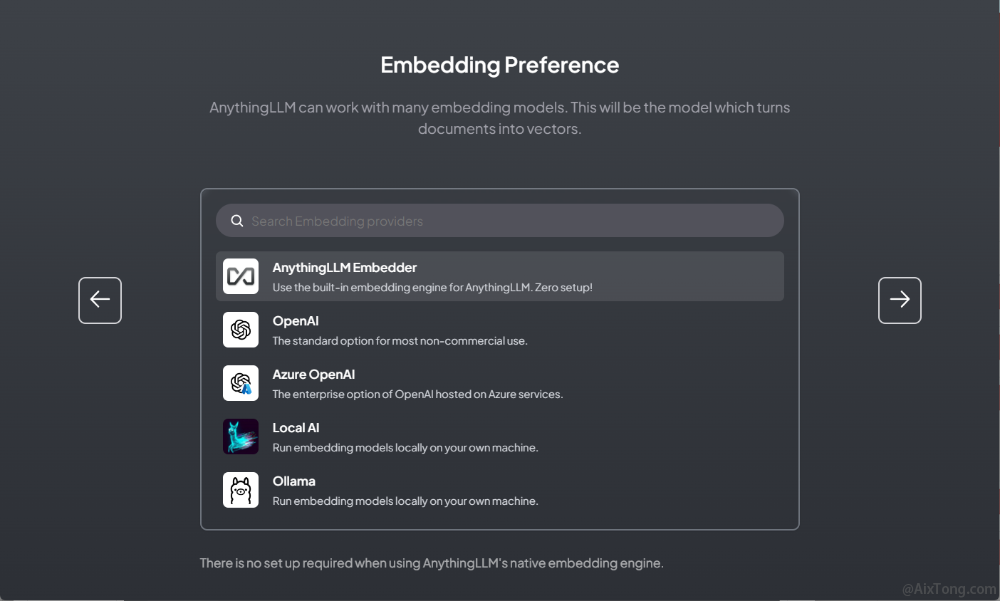
设置嵌入式模型
在此界面选择嵌入式模型。嵌入式模型用来将你将来提交的文档(用于知识库)转换为向量。这里选择AnythingLLM Embedder。使用AnythingLLM Embedder的嵌入式模型不需要做其它的配置工作。
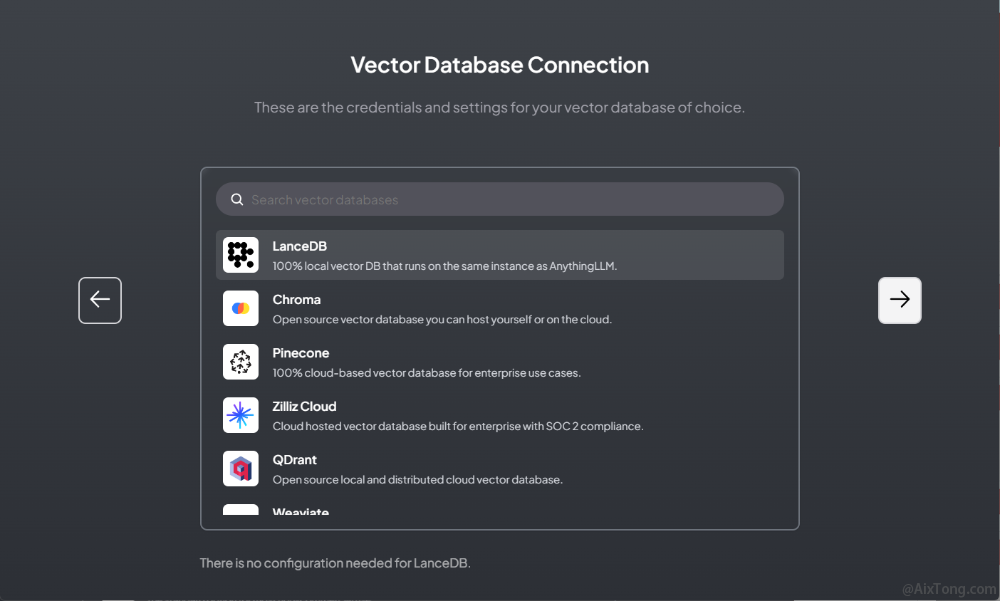
连接向量数据库
LanceDB是默认的向量数据库,使用该数据库不需要做额外的配置。
总结页
显示你之前的各个选项。
调查信息提交
在这个页填写你的邮箱,用途等内容。你也可以点击下面的Skip Survey跳过此页。
填写工作空间的名称
为你的工作空间填写一个名称。
进入应用界面
填写完成后,将进入应用界面。界面右上角显示正在下载的模型,左侧会显示你的应用空间名称。左侧下方显示一些操作按钮。
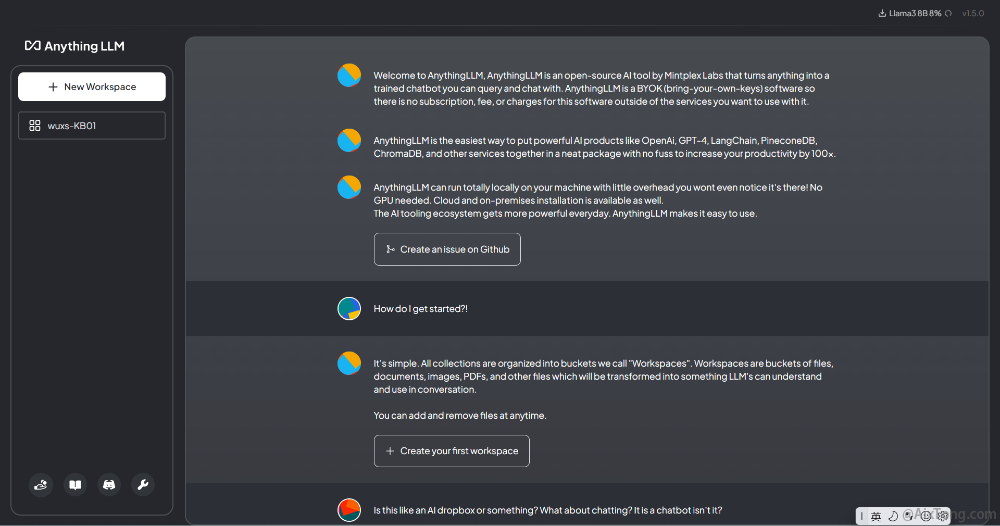
上述英文内容的意思如下:
1、欢迎使用AnythingLLM,AnythingLLM是Mintplex实验室的一个开源人工智能工具,它可以将任何东西变成一个经过训练的聊天机器人,您可以查询和聊天。AnythingLLM是一款BYOK(自带密钥)软件,因此除了您想要使用的服务之外(比如你想用ChatGPT作为对话的大语言模型,那可能需要给ChatGPT交费),该软件不需要订阅、收费或收费。
2、AnythingLLM提供了将OpenAi、GPT-4、LangChain、PineconeDB、ChromaDB和其他服务等强大的人工智能产品整合在一个简洁包中的最简单方法,无需复杂设置即可将您的生产力提高100倍。
3、AnythingLLM可以在您的机器上完全本地运行,开销很小,您甚至不会注意到它就在那里!不需要GPU。云和本地安装也可用。人工智能工具生态系统每天都变得更加强大。而AnythingLLM使其易于使用。
4、如何开始使用?
很简单。所有集合都被组织到我们称之为“工作空间”的桶中。工作空间是文件、文档、图像、PDF和其他文件的桶,这些文件将被转换为LLM可以理解并在对话中使用的内容。您可以随时添加和删除文件。
5、这像是一个人工智能的投递箱还是什么的?聊天怎么样?这就是一个聊天机器人吗?
AnythingLLM不仅仅是一个更智能的Dropbox。
AnythingLLM提供了两种与数据对话的方式:
查询:
您的聊天(提问)将在其可以访问的工作区,依据文档数据或推理,来返回数据(答案)或界面。将更多文档添加到工作区会使其更智能!
对话:
你的文档和你正在进行的聊天历史记录都会有助于LLM来丰富知识,而这些非常适合添加实时的基于文本的信息或LLM可能存在的更正和误解。
您可以在任一模式之间切换正在进行的聊天!
三、开始使用
后台的大模型下载完后,就可以开始使用了。
上传文档
选择你的工作空间,并点击上传按钮,进入文档上传界面。
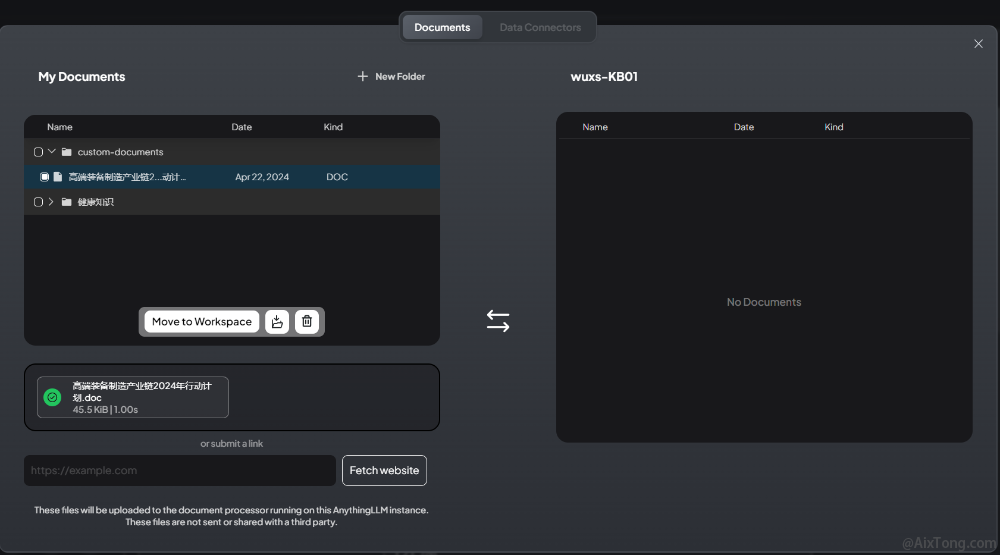
在上图的界面上,上传文档,并添加到工作空间。点击Save And Embed进行入库操作,等待一会后提示你更新完成。
你也可以将一个Web地址提交到库中以进行检索。
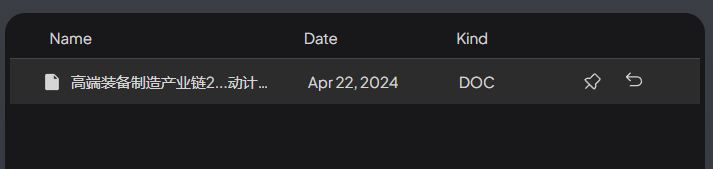
在这个操作界面,你可以将此文档固定到这个工作空间,也可以移除。
提问和对话
提交文档后,我们就可以开始对话了。可能是因为我的电脑配置不高,等待时间挺长的(大约需要几分钟)。但查看GPU资源使用情况,也不高呀。
咦?好象没有什么结果。
更换了一种提问方式,依然没有结果。难道不支持中文?换个文档(txt格式)试一下。
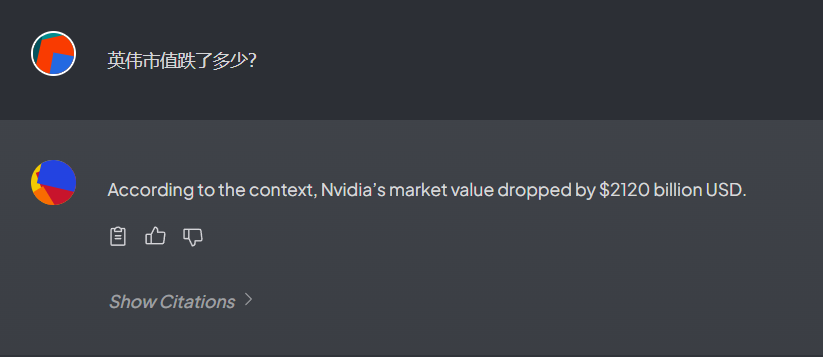
回复好象对了,但数值有误。原文中英伟达市值下跌了2120亿美元,而回复的内容是2万亿美元。明显不正确。但总算是有了结果了。就是速度太慢。
再换个英文文档试一下。这次我们提交了一个英文网站的链接,内容同样是有关英伟达的股票价格等信息。
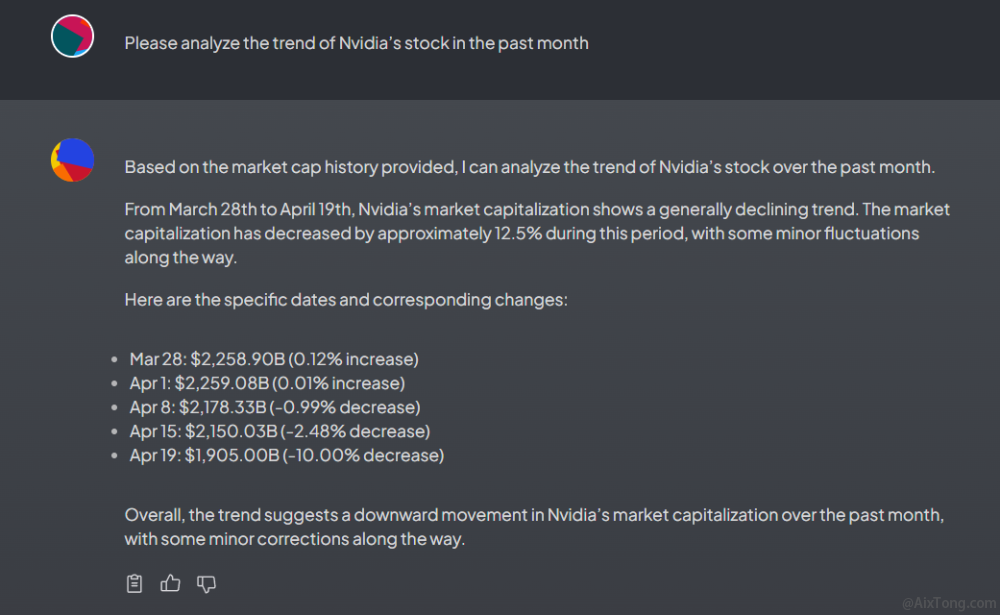
这次的表现挺好,给出了英伟达市值的最近一个月的变化情况。并且回复速度也提高了不少,看来其对英文的支持更好一些。
让AnythingLLM用中文来回答
我们修改一下提示词,就可以让它来用中文回答我们的问题了。
点击工作空间的配置按钮,进入Chat Setting,找到下面的Prompt,将默认的提示词略微修改一下就好。
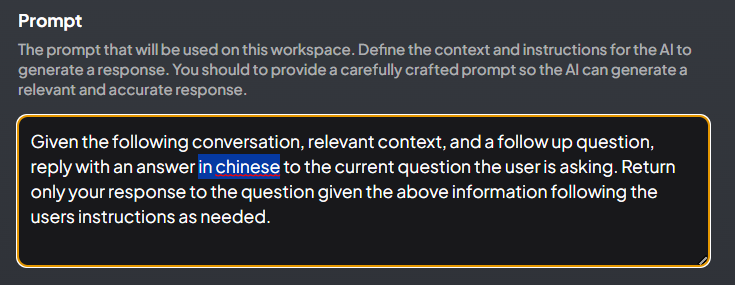
在图中answer单词后面位置增加“in chinese”,然后回到对话界面,我们再试一下:
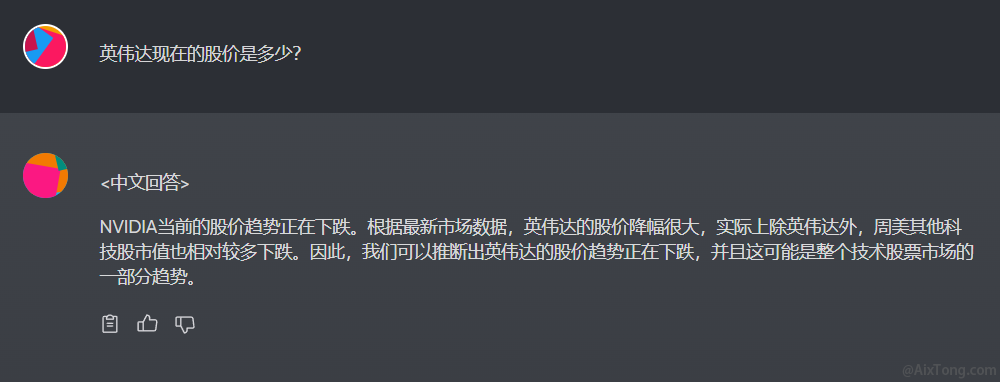
嗯,不错,这正是我们想要的结果。
查看回答的资料来源
点击回答内容下方的Show Citation,会显示当前回答从哪个文档中来。
提高答案的准确性
在AnythingLLM中,通过设置,可以提高答案的准确性。
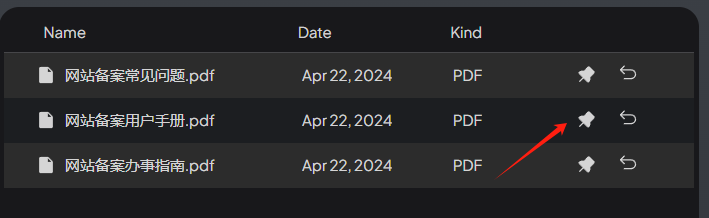
1、钉住文档
钉住文档后,则回答内容确认从文档中检索数据。这个设置可以极大的提高答案的准确性。
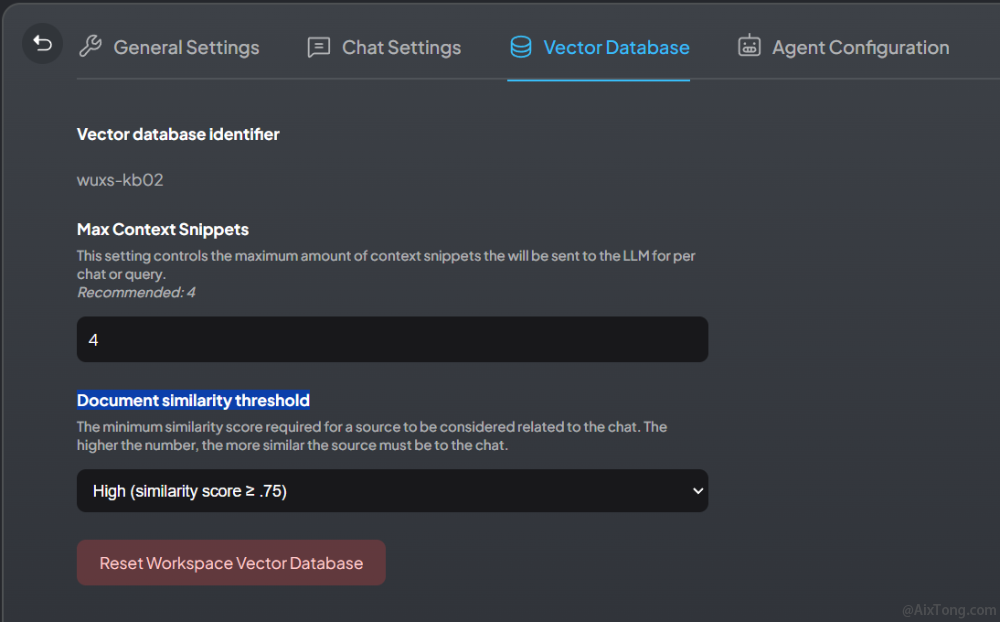
2、设置相似度值
在工作空间点击设置按钮,在界面上选择Vector DataBase中,调整Document similarity threshold值,可以设置其相似度。
有三个选项:25%,50%,75%。
参考文档
本文内容参考了以下网上资料:
1、AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)-CSDN博客